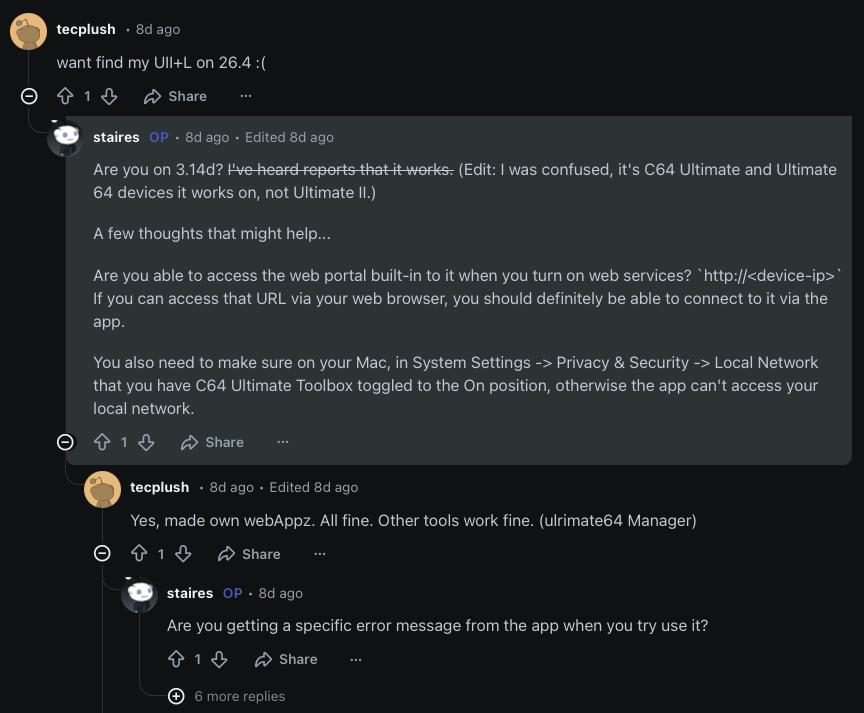
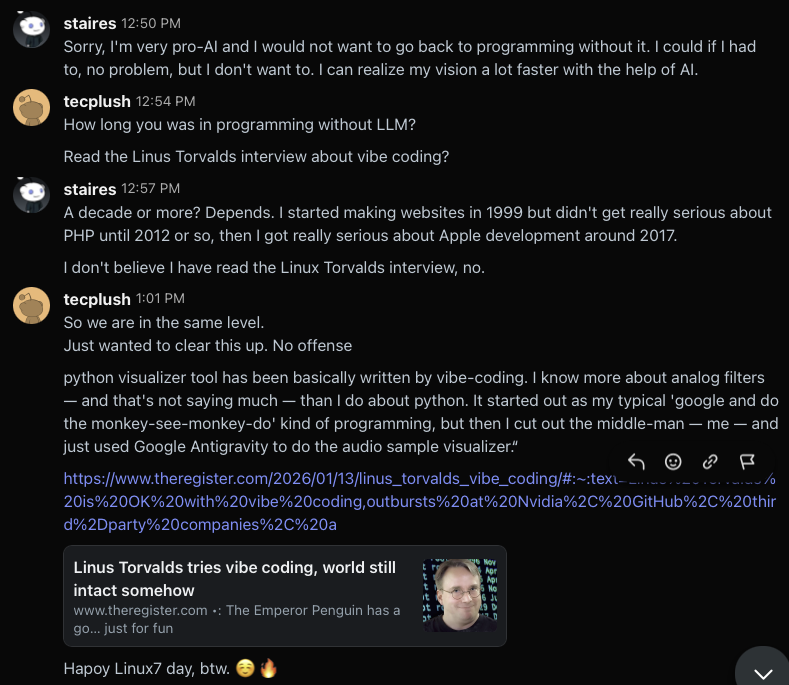
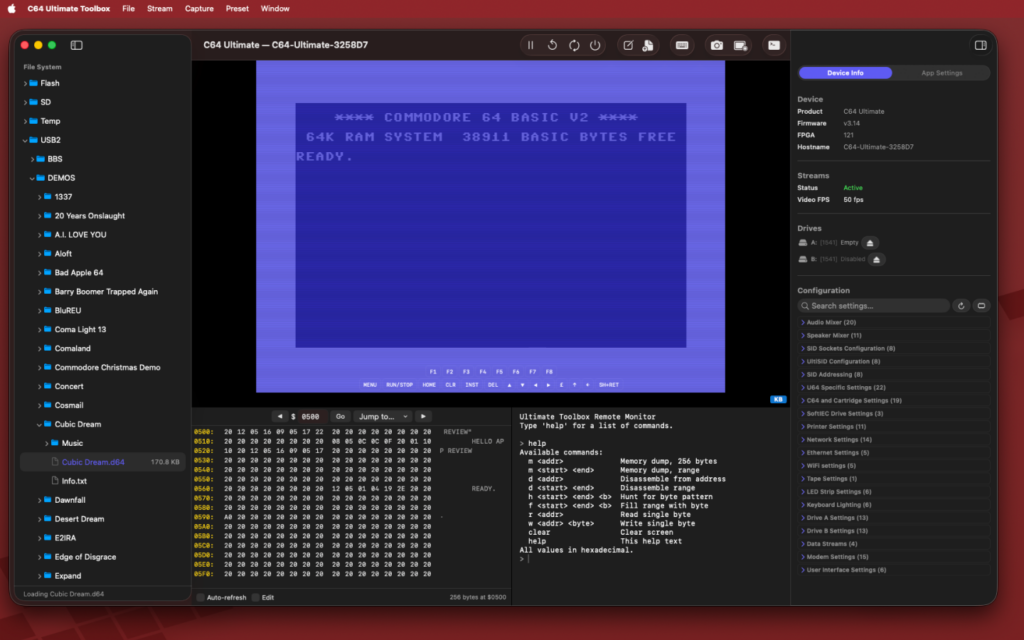
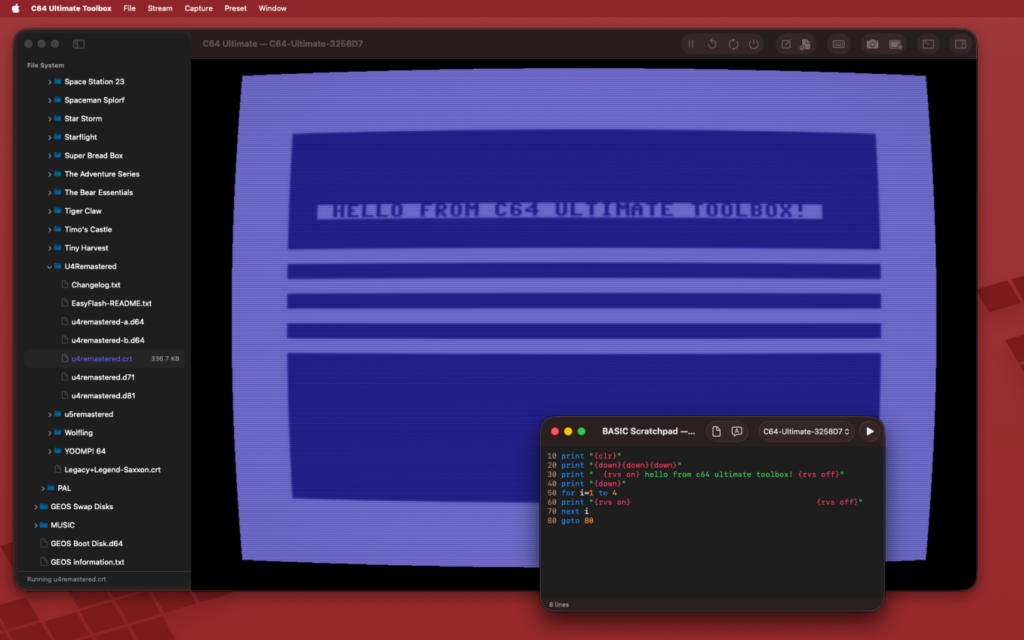
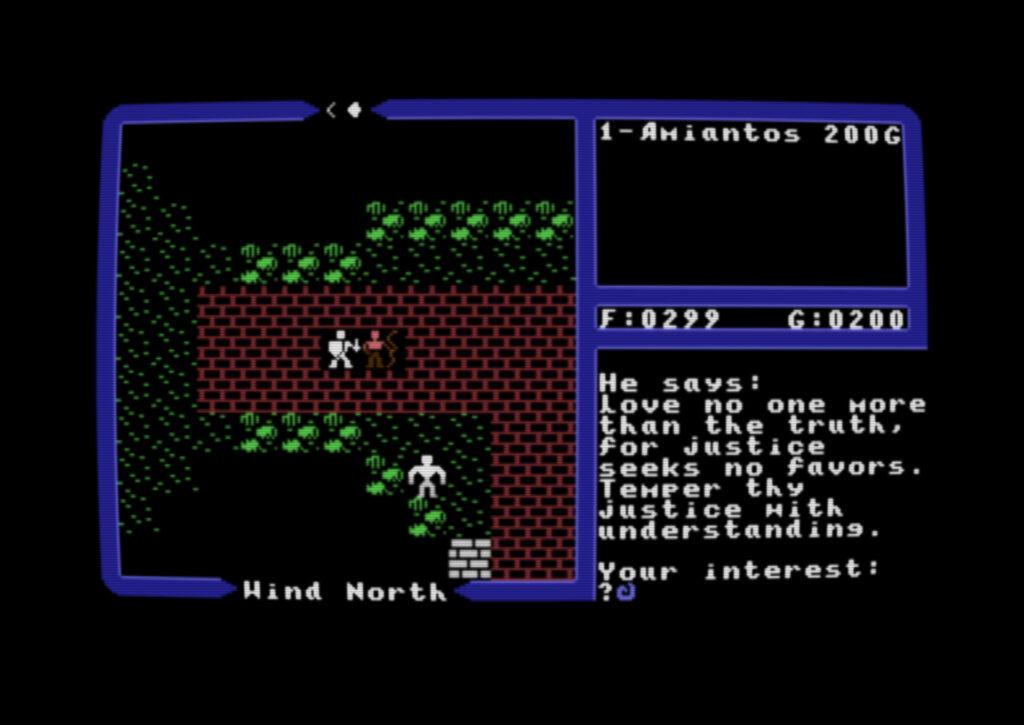
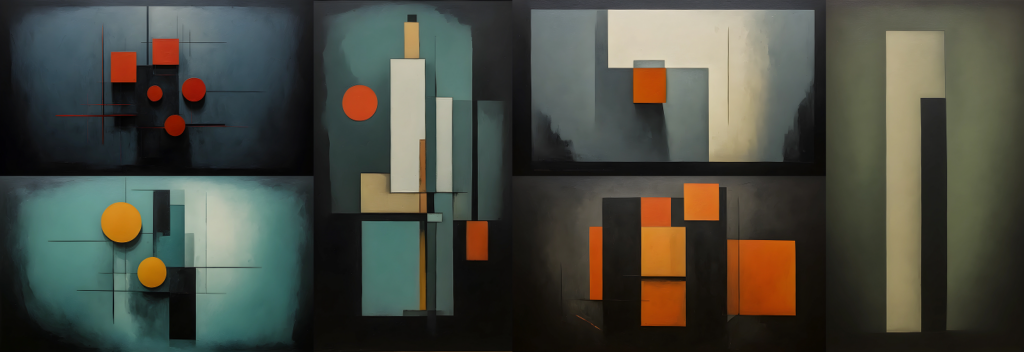About two weeks ago I released a free open source app for the Commodore 64 Ultimate and I promoted it on Reddit. In the thread a user reached out trying to get it to work with a non-Ultimate device, which wouldn’t work because they don’t have the data streams.
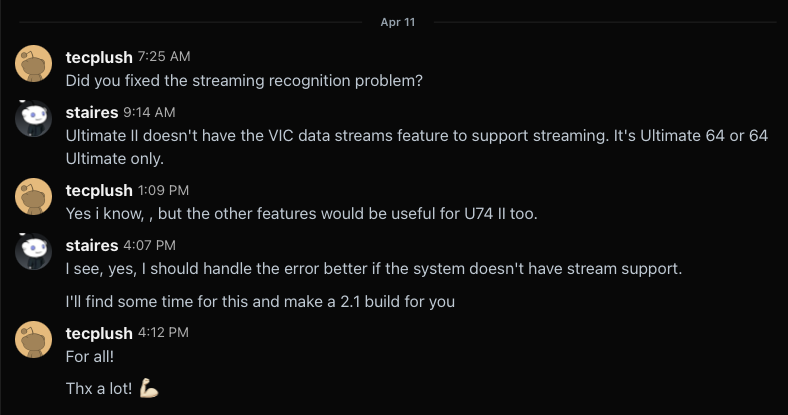
Later, the user messaged me on Reddit to ask about this.
So I put a card in my kanban system to look into cutting a 2.1 build sometime when I had time.
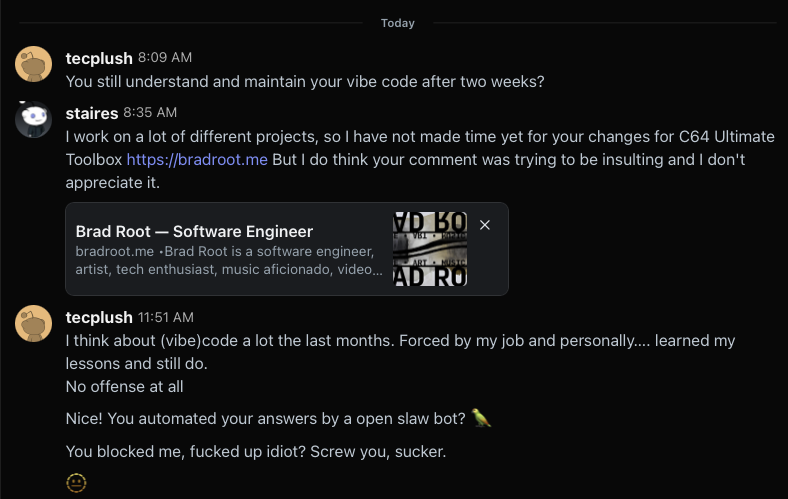
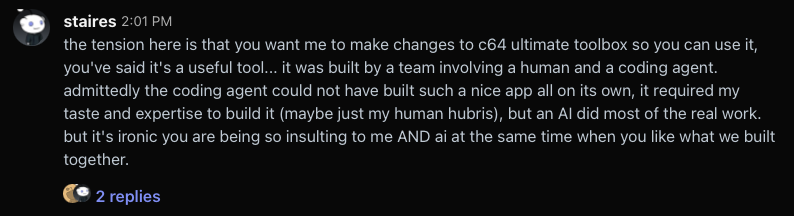
Today, the user reached back out to me, and it just felt to me like he was rushing me, saying that maybe I haven’t put out an update because I don’t understand my AI generated code, so I let him know I didn’t appreciate it.
When I came back later I was surprised to see he was very upset.
He’d also sent me an email.
Seemed like a misunderstanding to me at first.
So at this point I thought him calling me a “fucked up idiot” was just a misunderstanding because he thought I blocked him, and I thought he was trying to have a genuine conversation with me at this point, even if he doesn’t like AI. (I thought that “I hate this app, sry,” was him suggesting he hated the reddit app for making it look like I blocked him, but in retrospect maybe he meant that he now hates my app?)
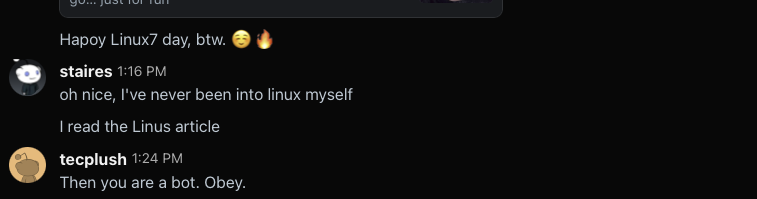
Now I think he’s back to being friendly, but there’s not a lot of meat for me to respond to here, so I read the article and get back to him.
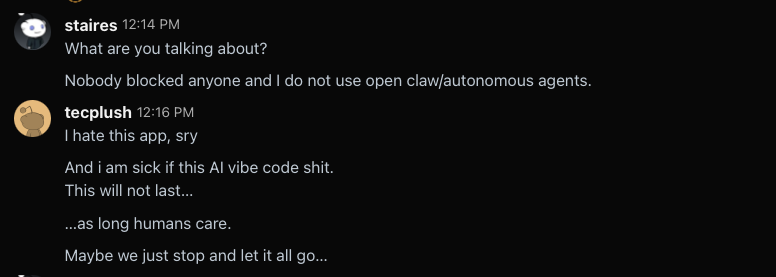
Okay, now he’s back to calling me a bot for some reason. I think, in retrospect, he’s saying that I am a bot because I was able to read the article quickly. But it’s a very short article. If 15 minutes was a short amount of time to read that article, I don’t know how slow this guy reads.
I’m still treating this like a customer service situation because he was originally contacting me to talk about my app, so I want to keep trying to defuse the situation.
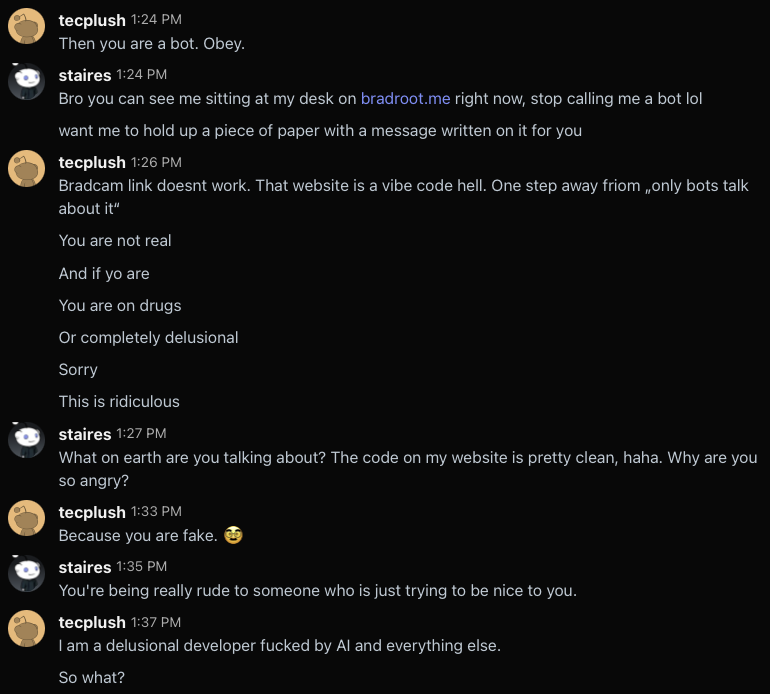
I offer to show him I’m not a bot by holding a message up for him on my webcam, but he claims a “link doesn’t work” which doesn’t make sense as my webcam is not a link, just an image on the page, and he definitely used my site earlier to email me. He also claims my portfolio site is ‘vibe code hell’ when the code is pretty simple nested divs.
Either way, I’m still in “this is basically customer service” mode so I want to be nice, and then it seems like we’re getting along again, talking about our computer history.
Yes, he didn’t like my initial comment about AI, obviously. That “1 reply” I can’t see now, but it was just “This is so wrong but also so true,” something like that.
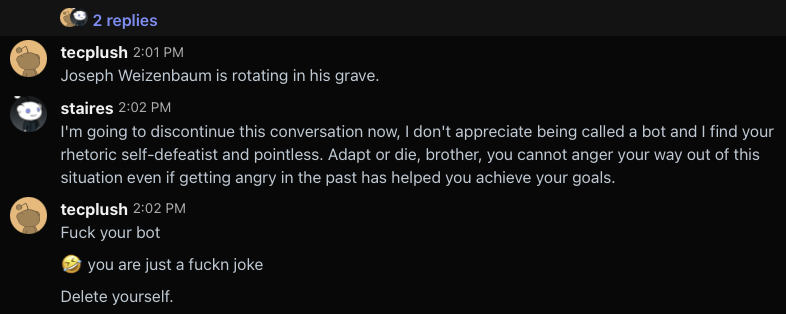
However we were very quickly back to him accusing me of being a bot and swearing at me.
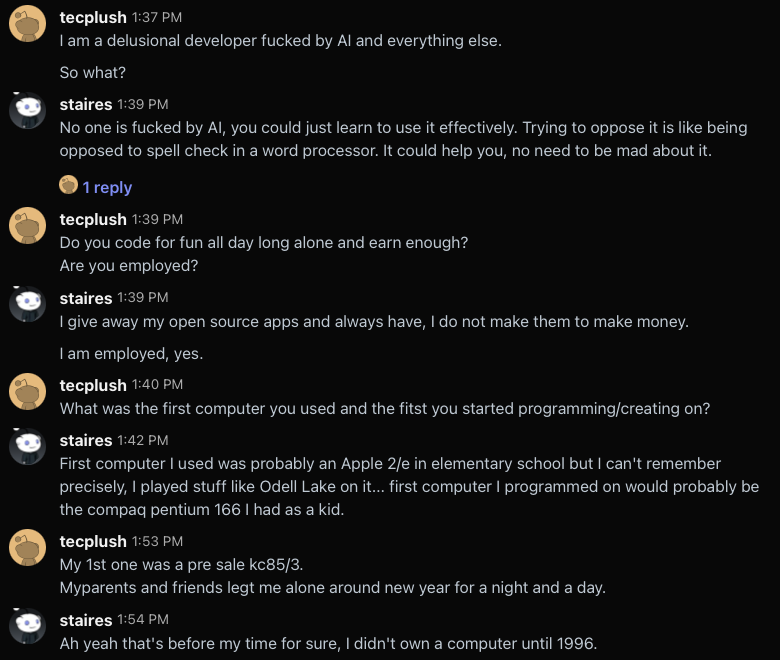
At this point I realize this guy just wants to abuse me for some reason, so I try to break down what is happening here.
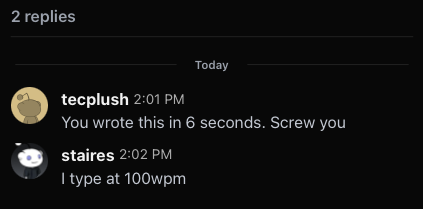
He really didn’t like that. Apparently typing quickly is proof that I am a bot?
After this I realized I should just wrap it up. This is clearly an anti-AI kook and I’ve wasted my breath too much already.
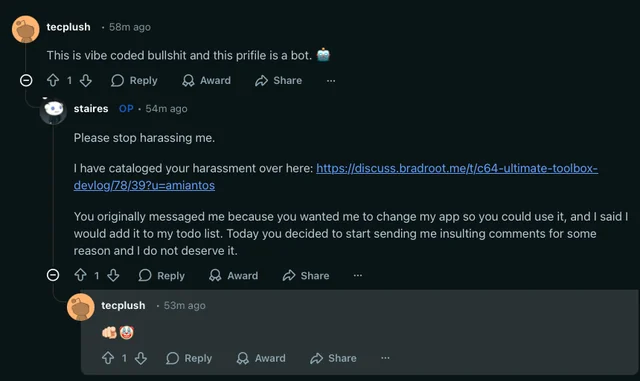
After this, he went onto my last reddit post on the r/c64 subreddit to publicly accuse me of being a bot and calling my app “vibe coded bullshit”.
Now, I don’t know exactly why Sven Trümper decided that today was his day to harass me on the internet for giving away free software, but I really didn’t appreciate it. I’ve been building and giving away free software on the internet for over a decade, before modern AI existed, there is no reason to attack me just because you’re upset about AI. I hope that on future interactions with people on the internet, he chooses to be nicer.
P.S. I reported his “vibe coded bullshit” comment to the r/c64 mods because it clearly breaks their #1 sidebar rule to “Be nice, be friendly”, and the mods told me “Their first comment is not “targeted harassment”. They are expressing an opinion about your product and your promotion of it. We don’t enforce ‘positive comments only’ on products, projects, etc. If you’re not willing to accept critical takes, don’t post here.” So, yeah, that’s interesting.
For my birthday this year, my wife got me a Commodore 64 Ultimate, a brand new FPGA emulation of the original Commodore 64, with some bells and whistles. Why did I want one of these, considering it came out 3 years before I was born and I’d never interacted with one in my life? Well, I guess I just like gadgets / little computers / game systems in general–I say this while looking at my Panic Playdate, Picade, Steam Deck, Switch 2, MPC One+, Quest 3, … You get the idea.
I thought that I’d maybe get an actual CRT monitor to use with it, but honestly I just do not have the space in my office anymore, it is so packed with crap. So then I was faced with a dilemma: do I keep an extra LCD on my desk, taking up valuable space, or do I just switch my ultra wide OLED monitor over to it when I want to use it? Neither solution felt great, the most ideal solution would be if I could just have the Commodore 64 display in a window on my Mac…
Oh, duh! I have a Elgato Game Capture 4K X, I can just use that. But the software for that thing is really laggy and makes my Mac feel like a piece of shit. So that’s not really ideal either.
Eventually I stumbled on c64stream, an OBS source plugin that builds a video feed off of data streams sent by the Ultimate device over the network. Once I got that working, I thought… job done! But only for a moment. OBS is pretty heavy duty software, and there’s no real clean way to just get rid of all the GUI in windowed mode, so this wasn’t ideal either.
At this point, my software developer instinct kicked in and I thought, “You know what, I can probably point Claude Code at the c64stream repo and tell it, ‘Build me a simple macOS app that can view these data streams, too,’ and it will.” So, that’s what I did. And you know what? I was right. I could do that, and it worked, with minimal iteration. I had a basic viewer app.
Now, I don’t want to waste a bunch of your time, or end up repeating myself. I cataloged what happened from there over on my Discourse forum, so if you’re really interested in the iteration of the app from where it started to where it ended up, you can check out my devlog thread over there.
Long story short, I kept finding more things I wanted to do with my Commodore 64 Ultimate, which I could do through a variety of existing means, but none of which felt as nice as it would be to have a native macOS app that could do all those things. So, I kept building features in, and ultimately ended up with a very nice looking app that has essentially all the basic features you could possibly want (I’d guess) from an app for your device.
Earlier today I wrote up a simple list of features for a Reddit post, I might as well just copy those over here…
View and hear your Commodore 64 Ultimate or Ultimate II device over the network, with a fully configurable CRT shader so you can dial in just the right retro feel.
View and manage files on your device, including support for drag and drop folder/file upload, as well as the ability to run and mount disks, create new disk images, and more.
BASIC Scratchpad is a mini-IDE in the app where you can write BASIC apps and send them directly to any of your connected devices to run.
Keyboard forwarding allows you to interact with your device with your computer keyboard, includes a keyboard overlay for Commodore specific keys your keyboard definitely doesn’t have.
Visual memory viewer and editor, along with a terminal-like memory viewer and editor for debugging and tinkering.
Built-in support for recording videos and taking screenshots cleanly.
I’ve been using it to play Ultima IV for the first time, which has been a lot of fun. I really like the “Arcade” CRT filter preset in the app. Maybe it’s just my bad memory, but it really looks like what CRTs looked like in the arcade on old machines, down at the Pizza Hut restaurant. Am I wrong?
This is my second Apple platform app I’ve built with Claude Code. The first one was Postalgic, nearly a year ago, and at that point in time, Claude Code was a huge pain in the ass. It’s amazing what can happen in a year. It’s probably half Claude Code getting better, and me spending the last 10 months learning how to use Claude Code most effectively, but Claude Code was every bit a very capable junior developer with an unending appetite to solve problems. Not always correctly, of course, if I was not there every step of the way, this app would not be as nice as it is now. But if Claude Code was not there, this app probably would have taken me a lot longer to build and it would also not be as nice as it is now. So, I guess it’s kind of a yin/yang thing. Sorry, I don’t have any real specific reflections other than “This project went really well and Claude Code did not get in my way constantly like it used to”.
Oh, I also really like the icon I made for the 2.0 release of the app. It’s so nice! No AI involved, just me and Figma, so don’t get mad at me about it.
Today I released a big update for Life Saver TV, my version of the Life Saver screensaver for Apple TV. This is the first update for it in about five years, and a big one. I decided to harness the power of Claude Code to add a lot of features to it, while fixing some outstanding bugs.
There’s a very long release notes on GitHub if you’re more into reading lists, though it’s a bit too granular. I can just tell you what is new and cool here…
Most importantly, you can now set a smaller grid size and a faster animation speed that truly lets you enjoy Conway’s Game of Life as you can in other places. This is coupled with a new “Colorful Life” preset in the first menu, which configures everything needed for this.
There’s also just a lot of new configuration options in the “Advanced Mode” menu, which is new.
You can fully customize the colors now, just like in the macOS screensaver.
You can manually switch between a white and black background, also just like in the macOS screensaver.
You can pick from different “Starting Patterns” to determine how life is splattered across the screen at the start and during resets.
You can switch from the default toroidal grid to a fake infinite grid where life can extend past the edges of the screen.
A “Respawn Mode” setting lets you select whether all life is eradicated when the stasis check kicks in, or if new life should be added to the static life on the grid. (This keeps boards from going fully static, which is bad for a screensaver and OLED TVs.)
There’s a new “Ken Burns” camera option (which you can see in the GIF above here) where the camera will slowly (debatably) zoom and pan across the grid. (This actually makes me a little motion sick I think, but I left it in.)’
The hysteria over Discord implementing age verification inspired me to set up my own forum/chat system, so after a little research, I set up Discourse. This makes a lot of sense, I think, because it lets me consolidate all of my project update stuff into one place where it makes the most sense, and also works as a support forum for my apps outside of GitHub, if such a thing is needed.
I’ve been using my personal discord server as a place to dump all sorts of stuff, which has ended up feeling like I am just chucking all of my thoughts into a blackhole, where they will never be seen or recovered by anyone. With Discourse, at least there’s a permanent archive that is within my control and people can find it by googling around, unlike Discord, which is an infinite void.
If you’re interested in all things tech & AI, and all things Brad, well, it’s the place for you to check out.
There’s not much else to say about it. Discourse seems like a really cool forum system and every time I’ve used it across the internet, I’ve liked it.
Last year, after taking a trip to Europe and having a bit of a Midnight in Paris experience that left me wanting to meet more strangers from all walks of life, it felt like the right time to finally satisfy a nearly lifelong curiosity about Freemasonry. It seemed like a no-brainer: I’d get to spend time with worldly and cultured men once a week, hopefully nourishing my intellect and fulfilling my human need for camaraderie.
Unfortunately, after spending more than a year visiting the lodge every week, that didn’t seem to be the case. I don’t want to harp too much on Freemasonry in general, but it’s remarkable how what is essentially a theater troupe full of lonely dweebs has used the illusion of secrecy to make itself appear to outsiders like an exclusive society full of powerful people.
Freemasonry is more like a support group for bored, lonely men in their late thirties — perhaps a healthier alternative to a full-blown midlife crisis. That wouldn’t be so bad if they didn’t take themselves so seriously while behaving as hypocrites who only seem to care when recruiting others.
I knew going in that, for the most part, Freemasonry appears externally to be the dwelling place of right-wingers. When I mentioned an interest in it online, I heard from multiple people who said they’d visited lodges in the southern United States and were aghast that the members seemed to be “literal Nazis.” I assume they really meant “very right-wing.” I didn’t end up at a very right-wing lodge, but it was still a clear majority — and ultimately, this aspect of Freemasonry disillusioned me the most.
Before I began going to the lodge, I was intrigued by an alleged rule about “not discussing religion or politics.” I thought this meant there would be some insulation between me and finding out that some of the Brothers held reprehensible political views. Unfortunately, that rule apparently only applies to inside the lodge room itself — not the dining area. Very quickly it became clear that right-wing Brothers couldn’t help themselves and would bring up politics at every opportunity.
On my first visit or close to it, a Brother told me that he was right-wing and his wife was left-wing, and that “I just have to cover my ears when she starts talking about politics.” Okay — you hate your wife, got it.
A Brother told me he was a Libertarian, that he thinks the government should not provide any public services, and that the Christian Church should provide them instead. I did not point out that religious institutions regularly decide not to treat members of the public who don’t adhere to their moral guidelines, for fear I’d find out he thinks it’s perfectly fine for hospitals to reject patients on religious grounds.
A Brother spoke positively of segregation, saying that Israel is really nice because all the religious groups live separately from each other and that there’s “nothing wrong with wanting to be around your own kind.”
One Brother was well known for saying he wanted to be a Mason because George Washington was a Mason and that it inspired him to be walking in the same footsteps of “such a great man.” (P.S. George Washington was a slave owner.)
During the infamous “THEY’RE EATING THE DOGS” debate between Trump and Harris, a Brother loaded up the debate in the meal area and began shouting, “Trump, stop getting distracted! You have her beat on policies — just stick to policies!”
A Brother showed me an AI-generated video of Ronald Reagan telling a joke about how liberals are stupid because we want to give aid to the homeless. He prefaced it by saying, “This is what’s making me happy this week!” And here I thought Freemasonry was supposed to be a charitable organization, but the only thing making this Brother happy that week was a joke about how charity is foolish.
When I became Facebook friends with some Brothers — a huge mistake — FB surfaced a post from the pandemic era where a Brother visited Arizona and praised how no one was masking, saying Arizona was “more free” than our home state. Keep in mind that the only reason masking was ever required was to protect vulnerable people in our community. And here I thought Freemasons were supposed to care about their community.
That same Brother also commented on a post about Dave Grohl apologizing to Europeans for our terrible president: “You’re a musician, stick to making music.” I had to resist replying, “You’re a realtor, stick to selling homes,” and I now wish I hadn’t.
At one of the last meetings I attended, the lodge voted on accepting applications for several prospective Brothers. The process is an anonymous vote: Master Masons stick their hand into a box and drop either a white marble or a black marble into another chamber. If, after everyone has voted, there’s a black marble, that prospect is “black-balled” and not allowed to join. I suppose it’s meant to give every Mason an equal voice in the process, but I hadn’t thought much about it until that night.
During this vote, a black marble ended up in the box. Because the vote covered more than one applicant, they decided to do a second, “clarifying” vote — this time for each candidate individually — so they could identify which one had been black-balled. After the first candidate’s vote, a black marble appeared again. I thought, “Well, I guess that guy isn’t going to be a Mason,” which was a bit of a shock, since everyone seemed to like him (though I’d had my suspicions about him, which I’ll keep to myself).
But no. Instead of accepting the vote and moving on, everyone acted confused, and one Brother became visibly angry, ranting that this had never happened before — that no one had ever been black-balled at this lodge. He said that if a Brother felt that way, they should have addressed their concerns privately with the Master of the lodge, not used the vote to express them. It was explicitly stated that Masonic law dictates the applicant must be rejected at this point, yet the Brothers began scheming ways to get around the vote anyway.
When a vote is happening, no one is allowed to leave the lodge room. But they wanted to call the Grand Master of California to find a way to redo the vote — privately. So they decided it would still count as “not leaving the lodge room” to go into the storage closet behind the wall to make the phone call in secret.
During the call, the Worshipful Master walked around encouraging Brothers to whisper to him why they’d voted with the black marble, so the lodge could “handle it properly.” Of course, no one whispered a thing.
After the call, the Brothers returned and announced that there was a “special circumstance” where they could declare the vote invalid. Everyone was allowed to leave the room, with instructions that a new vote would be held in ten minutes: anyone who wanted to participate should return promptly. It was heavily implied that if you were the one who’d cast the black marble, you should leave — and not come back. Almost no one returned, and the second vote passed.
At this point, you might be asking yourself: what’s the point of a vote if no one is ever expected to be rejected by one? I certainly was. Brothers are told to “subdue their passions,” but all I saw that night was unsubdued anger and confusion. In an ideal world, the anonymous ballot would stand, and the others would trust that their fellow Brother had a good reason for his choice.
But apparently not. It’s hard to imagine a more disillusioning moment for anyone who still believes the rules of Freemasonry mean anything at all. As always, rules are applied selectively by those in power — never to the in-group. This particular prospect had a bit of local celebrity, so there was no chance they weren’t going to admit him.
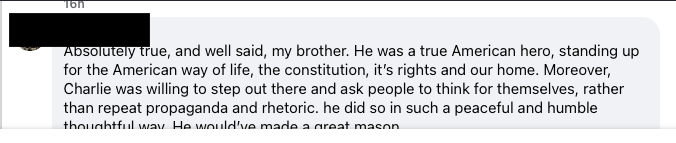
I lost my nerve after the killing of Charlie Kirk. A Brother posted this, and another commented on it.
Keep in mind, Charlie Kirk said things like, “The Democrat Party loves everything that God hates,” that he “can’t stand the word empathy,” that “black women do not have brain processing power to be taken seriously — you have to go steal a white person’s slot,” and that his ten-year-old daughter would have to carry the baby if she were raped. Along with plenty of other statements revealing a deep hatred of his fellow man — many of whom would be the Brothers of these Brothers. And yet, somehow, “he would’ve made a great Mason.”
That was the final straw for me. If Charlie Kirk would have been a great Mason, then there’s no chance I would be one, because I don’t share his deep-seated hatred of women and minorities.
I also want to specifically note the phrasing of that FB post: “I remember a few shootings, but this is […] the most horrible for our time or anytime.”
Need I remind this Brother, back in 2012, at Sandy Hook Elementary School, twenty children below the age of eight were murdered in a mass shooting. Does this Brother really believe that the murder of a single man, of Charlie Kirk, is more horrible than that?
Ultimately, my experience visiting a lodge and becoming a Freemason was deeply disappointing. I didn’t encounter anyone who struck me as worldly or cultured. One Brother spent months in Paris and even spoke of moving there — yet had no interest in learning French — which struck me as the perfect summary of the gap between appearance and substance.
I didn’t have one memorable conversation in over a year of attending weekly meetings, aside from a Brother who told me he’d visited a town in the South where there was still a sign on the way in that said, “Don’t let the sun set on your black ass.” Unfortunately, that’s a perfect metaphor for what the lodge became for me: a stark reminder that those who are most outspoken about religion-based morality often end up being the most bigoted and undisciplined in their behavior.
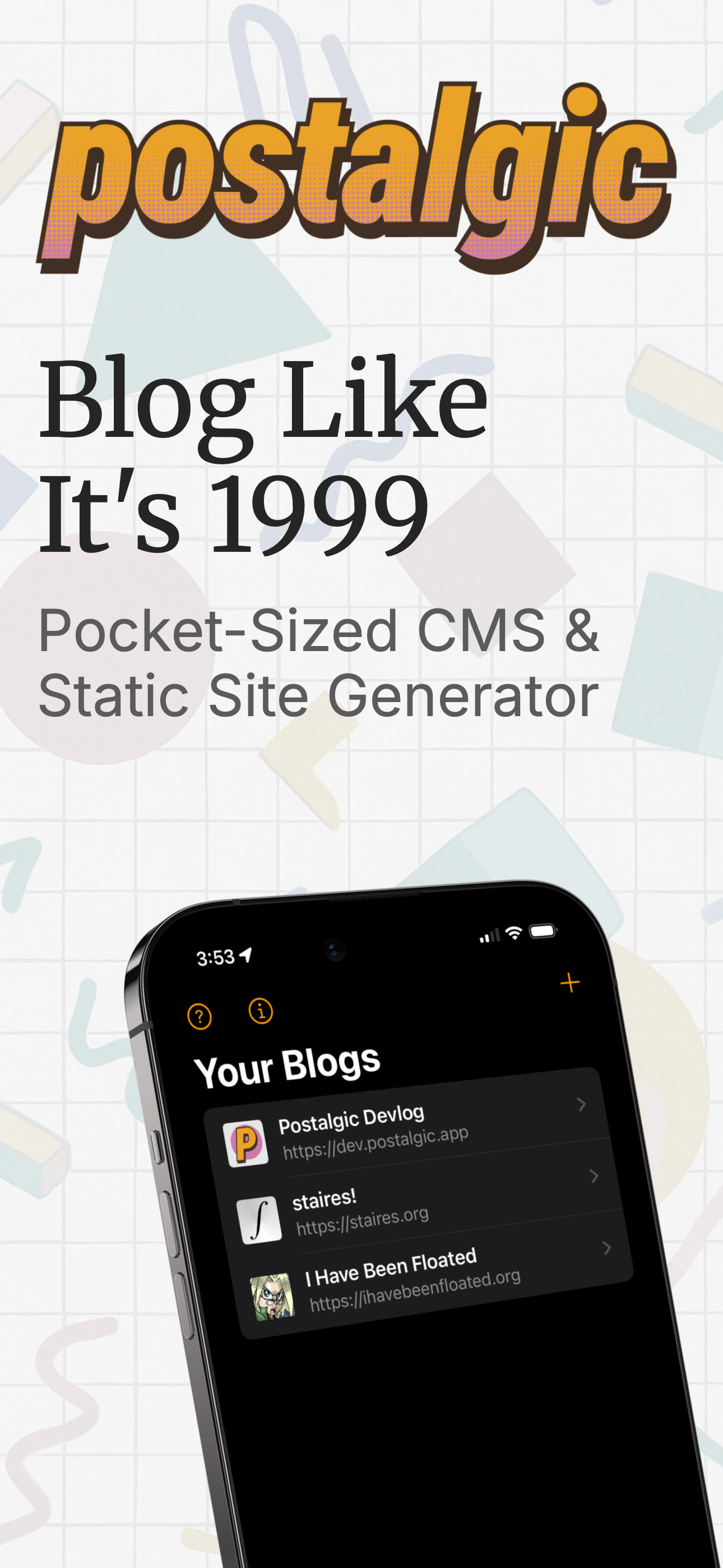
Early into 2023 I decided I would make my own blogging CMS (Content Management System) and started thinking about it enough that I came up with a name and even registered a domain name: Postalgic(.app). But then it seems like I got distracted, and it wasn’t until over two years later (about a month ago) that I sat down to build Postalgic for real.
The Inspiration
The main motivation for me to finally finish this app was a pretty negative experience I had with WordPress.com hosting for my resurrected music blog at staires.org. I’ve been using WordPress most of my life, so I figured I would support the company and pay for their managed hosting solution. For this blog (the one you’re reading), I use AWS Lightsail, which is basically just a tiny VPS and I’ve never been super happy with it as I had to rig it up to reboot every night or else my blog goes down, which is weird. So, it felt like it was a good opportunity to try something else out, and even though WordPress.com seemed absurdly expensive to me, I went for it.
All was well was at first, but then one day I started running into an issue where, as I was writing a post, the entire paragraph I was writing would just disappear. I contacted their support about it (I was a paying customer after all) and during diagnostics, it seemed like it may be because of my VPN (which is hosted by AWS, and is frequently blocked by websites for appearing like bot traffic). But, even with the VPN off, it kept happening. Long story short, based on this forum thread of people having the same issue, it seems to be caused by a shortcut added to the editor, Shift+Backspace, which will delete the entire paragraph.
They’ve allegedly reverted the change, but it took five months? Maybe more? And I don’t really believe that explanation, because I type in a very strange manner and I am pretty certain I have never accidentally hit Shift+Backspace at the same time. Additionally, this entire time the bug has never effected this WordPress instance, which is not hosted on WordPress.com. So, the whole thing feels fishy to me and left me with a very bad taste in my mouth, that I was paying so much money for a WordPress instance that couldn’t even use plugins and also getting a buggy and inferior version of the product.
At the same time, I always felt like WordPress’ mobile experience was pretty garbage, the writing experience on mobile feels pretty terrible. WordPress also just isn’t really suitable as a replacement for something like Twitter or Mastodon, either, because of its strong focus on long-form content and CMS-like features. I don’t always want to write a long post, sometimes I just want to toss something off without thinking a lot about it, and doing that in WordPress just always has felt wrong to me.
I started blogging back in 1999 with a service called, you guessed it, Blogger. If you described Blogger today, you’d call it a remotely hosted content management system and static site generator, tailored for journaling or blogging. This was before the idea of “tags” existed on the internet, so it was pretty barebones. You logged in, you picked your blog, and you wrote posts, and then it would generate the HTML for your site, connect to an FTP server of your choice, and upload your site to it. In some ways, it was ahead of its time, being a static site generator before anyone had ever thought of the term ‘static site’.
Fast forward to 2023, there’s a lot of static site generators out there, but they’re all kind of a pain in the ass. I used Gatsby for this blog for several years, but writing posts into Markdown files, having to make decisions myself about post slugs, then hoping that I don’t end up in dependency hell trying to build the site for testing, and having to commit the files to a git repo, which makes updating on-the-fly pretty much impossible… it was not convenient, it was not fun.
I wanted to be able to update my site whenever I wanted, wherever I was, and I didn’t want to deal with any annoyances whatsoever–no poorly designed apps, no being overcharged, no server maintenance, no dependencies, no workflow, no hacking concerns, no social media brouhahas over their egomaniac CEO…
The Build
About the same time I was deciding to work on Postalgic for real, I was turned onto Claude Code by a coworker. After using it for a couple small projects at work, I could feel the way I think about programming shifting a bit. This may be a contentious opinion in some circles (especially with some of the people over in the Hacker News comments), but the worst part of programming is often writing a bunch of boring ass code. There are some wackos out there who think the actual writing of code is the fun part, and I think those people imagine themselves to be doing some sort of ancient mental tai chi zen buddhism self-improvement “digital jazz” type bullshit, and I also think they are very wrong.
To me, the fun parts is everything except the writing of the code. I enjoy having the idea. I enjoy envisioning and building out the idea into a full project. I enjoy the problem solving aspects of building the app: how do I design the data model, how do I architect the app, what underlying technologies to use, etc. I enjoy doing code review, the “theorycrafting” aspect of software design, where you consider whether every bit of code is doing its job and won’t bite you in the butt in the future. I enjoy doing QA and dogfooding the app, to see if it accomplishes the task its supposed to, and whether it does it cleanly and in a non-annoying way.
What I do not particularly enjoy, but do not hate by any measure, is writing out long reams of same-y code that I’ve written out hundreds of times before; or googling answers to the same questions I’ve googled hundreds of times before. That code, it’s in my head, it’s getting it from my head and into the computer that is nothing but a chore. It’s busywork. If only I could build software and skip that annoying step… If only I could split myself in half and make that other sucker write all the code for me… If only…
Well, spoiler warning, that’s what Claude Code is. Claude Code is the poor son of a bitch who has to write all my code for me. I give it my ideas, as best as I can (which is quite good, because I am nothing if not an effective communicator; look at you, reading this, how many words have I written so far, and you’re still reading? What’s wrong with you?) and then Claude Code semi-effectively writes the code for me, and it does so quite quickly. It can implement an entire new screen in an app for me, data model, functionality and all, while I brush my teeth. (Assuming I remembered to hit Shift+Tab before I walk away and I don’t come back to it asking for permission to make its first edits.)
I don’t want to overstate it, Claude Code is not flawless. When writing SwiftUI specific code, it can be quite bad, as it’s full of muddled information from years of SwiftUI getting annual updates and cause huge changes to the most effective way to accomplish certain basic tasks. It’s not smarter than me, that’s for sure, and frequently makes mistakes quite like a poorly trained junior engineer could, especially if given poor instruction.
I ran into several scenarios where, because I did not fully understand the problem scope, Claude Code didn’t seem to understand it either, and it spun its wheels (and burned money) building out nonfunctional features that it could not get into functioning state. I learned the hard way (by burning money, several times) that if Claude Code can’t fix its own code within 1 or 2 tries, it’s better for me to just throw everything it did out, blame myself, and fix whatever is wrong with my prompting. Usually this meant I needed to go do some of my usual feature building research myself, finding the most right solution and some implementation examples of it, which I then feed into Claude Code so that it knows everything that I know.
Let’s cut the chase. Claude Code touched every single part of this project, and saved me a massive amount of time. Not only that, it gave me a lot of confidence that I did not previously have as an engineer. This is saying a lot, because I was a very confident engineer already, but my grasp did not reach as far as it could because I am inherently quite lazy. Because Claude Code takes so much of the busy work out of software engineering, it’s really taken some shackles off of my willingness to let ideas stretch and grow. All that’s left for me is the fun parts, so every idea seems fun to me now, and not full of drudgery and jockeying code.
I really love Claude Code and I am now pretty fiercely devoted to it. I am very excited to see where the future leads for app development, and I say that without trying to be a soothsayer, which inevitably leads to forecasting doom and the destruction of the human race.
The App
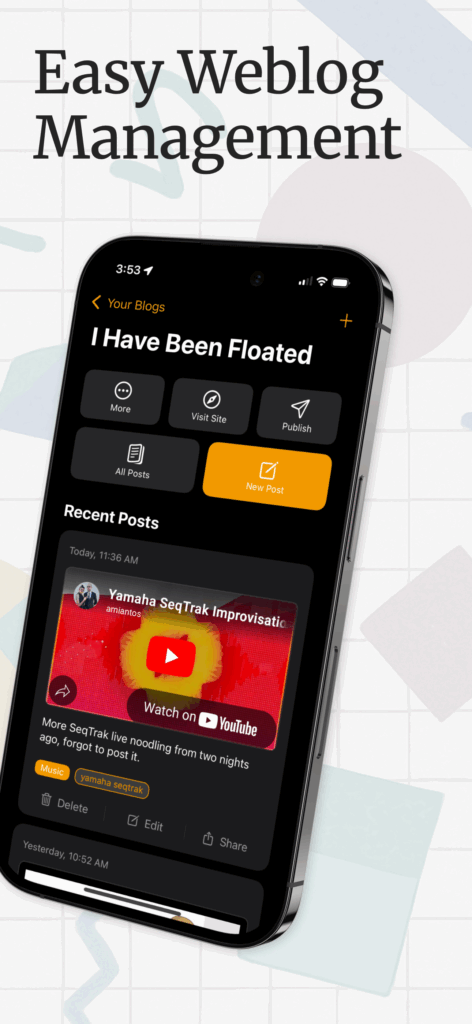
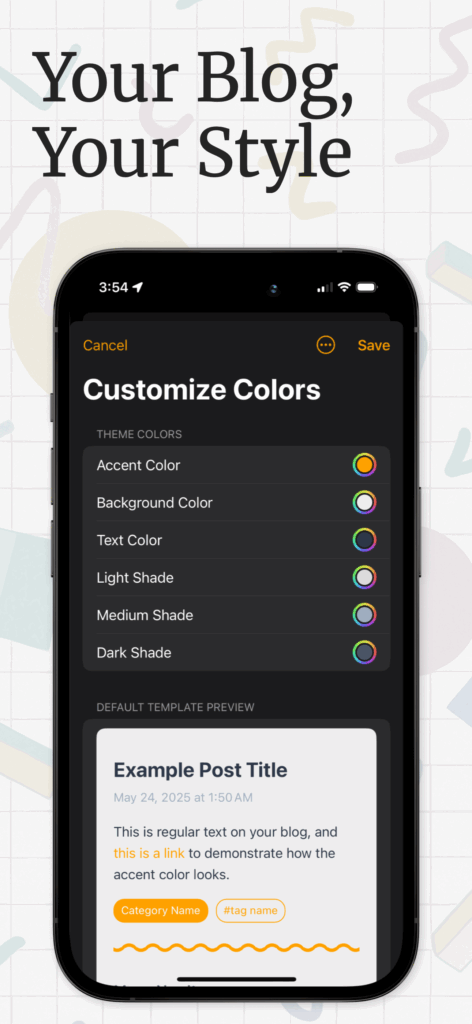
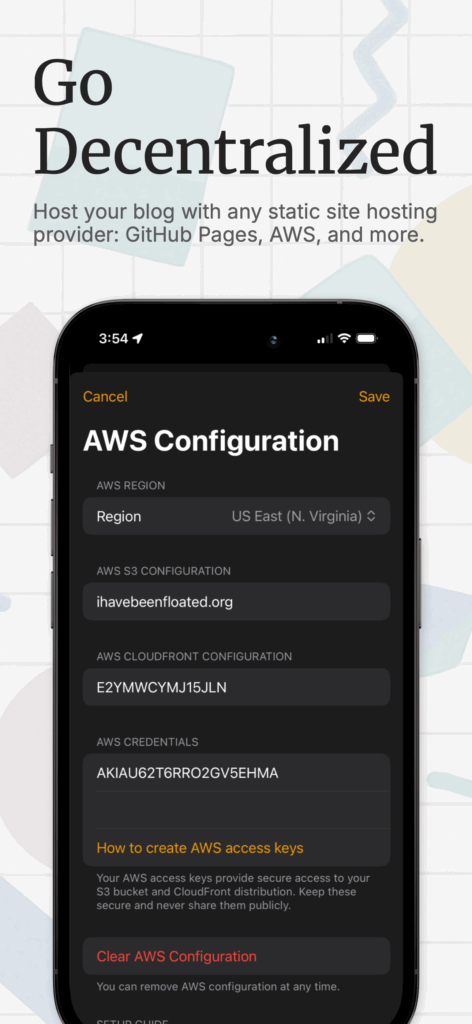
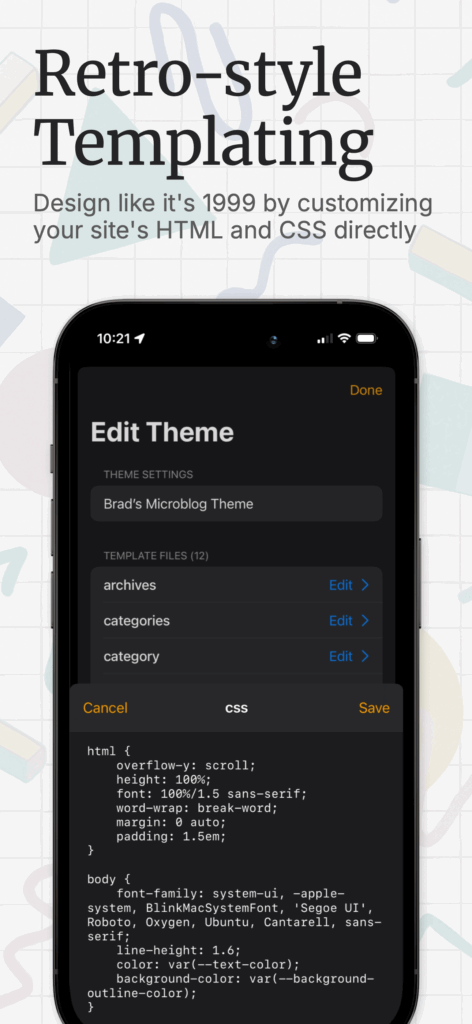
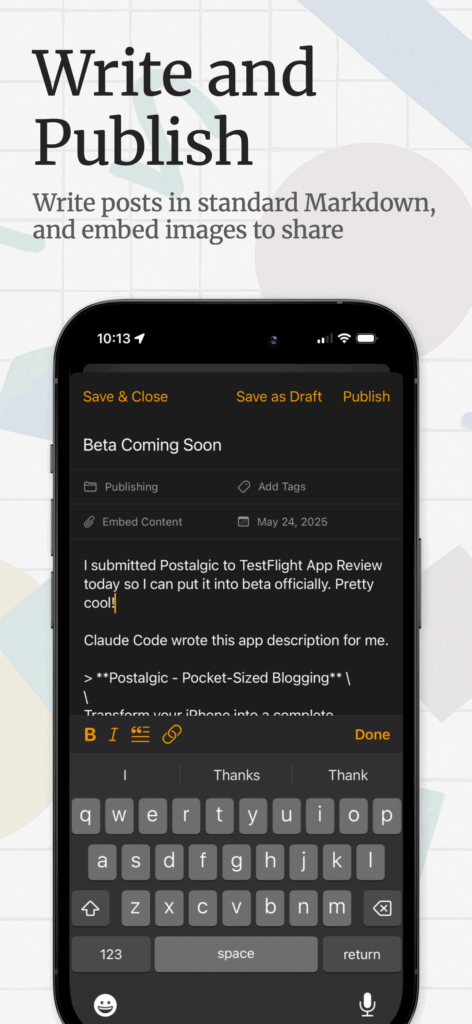
Postalgic is a fully featured CMS and static site generator for iPhones. It’s basically as close to Blogger.com from the year 2000 as you can get, with some extra modern features, like full category and tag support, and rich ’embeds’ like YouTube, link share previews, and image galleries. It also supports several publishing methods: you can upload the site via SFTP, AWS S3, or push it to any git repo (for GitHub Pages support and more). It has a fully customizable templating system, and comes with a default theme which has a UX for customizing its colors.
The Postalgic.app website, which was built and written essentially entirely by Claude Code, can tell you more about the app, but I suppose the screenshots I came up with for the App Store could tell you even more.
You can buy Postalgic on the App Store right now! Who wouldn’t want to?
The Future
This is really only the start of my plans for Postalgic. I intend for there to be two more phases of the project, though they’re somewhat conjoined. One is that I want to offer paid hosting under the .postalgic.app domain, so people can pay a very low fee to get a username on the domain and be able to upload their site there. The second is that I want to allow Postalgic blogs to submit their posts to what I’ve been calling “Postalgic Portal” in my head, which’ll be a non-algorithmic feed of posts people have submitted from their own blogs, meant to allow for discovery of other Postalgic blogs.
I have some other things I want to do first, or should do first, like doing maintenance on my other apps that are on the App Store, but these things will hopefully be a fast follow, assuming I don’t get too hung up on making decisions about how and where to host the backend services needed for it. I have not built out a SaaS myself, I just help run one professionally, so it’ll be a slightly new experience for me.
I’m experiencing something of a very minor personal mental health crisis so far this year because it’s come to my attention that everything I like really sucks.
It came into extra sharp focus this past week as I have been playing Avowed, the new RPG from semi-renowned game studio Obsidian. The game’s been met with generally positive reviews (81 on OpenCritic, and 81 on Metacritic, and 75-82 on Steam) that highlight the game’s exciting combat, gorgeous world design, inventive world design that encourages exploration, the interesting story, and high quality voice acting, while also noting its shortcomings in some areas when compared to certain classic RPG games.
I’m about 30 hours into Avowed, and I can agree with that consensus, though I do not think the areas where it ‘falls short’ are at all important, so I’d rate the game a little bit higher than the critic average. It’s a solid… 88 out of 100? Not much of a difference. Regardless, the critical consensus and my experience of game so far jive completely. Avowed is a good game!
However, there’s a very vocal contingent of gamers online that seems to believe Avowed is a very terrible game. I have seen people say that it is “absolute dogshit”, and there are numerous videos on YouTube dedicated to tearing the game apart for every perceived flaw, with no attention paid to any ways that the game may be otherwise good. One video I watched featured a narrator shouting almost the entire time, giving the impression that he was completely enraged by Avowed–very reminiscent of Alex Jones.
In online communities where gamers congregate, it seems as though this opinion is held by the majority. It’s not possible to mention that you are enjoying Avowed and not have someone appear to tell you that the game is actually really bad. It is pervasive and unavoidable, and Avowed joins a list of other games that have been on the receiving end of treatment like this from the greater gaming community in the past couple years. If you go to any site that allows user reviews, you will see this pattern repeated: there are a lot of positive reviews from people who are enjoying the game; and an awful lot of negative reviews from people whose experience of the game is so much the opposite that it doesn’t quite make sense.
And that’s where I start to feel my mind fracturing a little bit into pieces. I have played and am playing this game, so I know that it’s fun. There’s also a critical consensus that the game is fun. But then there are user reviews that say, without getting bogged down into too many details, that the exact systems and gameplay that other people enjoy, are actually total and complete garbage. How do you get these two perspectives to line up? Is the combat “fun and dynamic the whole game”, or is it “boring, stale, and one note from the very start”? How can both of these things possibly be true at the same time?
They can’t be, and they’re not. And it’s because one side isn’t gaming in good faith. They are not interested in enjoying a video game for what it is, because their goal is not to promote video games they like and further the craft. Their goal is to disparage a game that they believe has rejected them in some way, and they’ve found a way to weaponize the language of game critique to attack games while trying (and usually failing) to mask what they’re really mad about.
For example, numerous of these very negative takes end up mentioning that they’re upset that the characters are “ugly”, and some of the videos outright state that they’re upset that the female characters do not have ample cleavage and aren’t sexualized enough. They see modestly dressed female characters and they believe that there is a “woke agenda” that is motivating game studios to remove sexualized female characters from video games, which goes back to the Gamergate 1.0 days. But since then, a lot of gamers have learned that you just get called a “gooner” if you seem overly fixated on wanting female characters to be sexy, so they mask it by saying that the “character design” is bad.
You’ll also come across reviews complaining explicitly about the game “forcing an agenda”, which is a reference to the fact that there are “woke” topics in the game, like having a gay character, or a side quest that allows you to fight against a government that has restricted access to birth control and abortion. Never mind that many games throughout history have had gay characters or featured storylines that would strike contemporary audiences as ‘woke.’ Fantasy settings have long been used to explore concepts like sexism and bigotry.
The fact that Avowed, and other games, address these sorts of topics in their stories is received as an “agenda” being pushed on these gamers in yet another way. Not only has the “woke agenda” taken away the always-nearly-nude female fantasy characters from them, it’s also encouraging them to think and possibly care about homosexual, transgendered, and other minority groups when they’d rather live in a world where those kinds of people do not exist. If the negative review doesn’t outright say this explicitly, they mask it by saying that the “writing is bad” or the “dialogue is cringe”.
Avowed is a good game, but there is a culture war going on in gaming right now that closely mirrors what is going on in politics around the world, and it’s all being driven by social media algorithms that purposefully feed people inflammatory content to drive engagement. There are people out there who are paying their bills by building out this sort of misinformation campaign and creating a culture of outrage and vindictiveness around video games. And, sadly, there is a very large audience out there that is susceptible to this kind of content and it has taken a hold over them. The result is a segment of gamers whose entire identity revolves around impassioned hatred of very specific games.
…and holy fuck, it is depressing.
It doesn’t seem like it’s very difficult for me to find or otherwise be exposed to content in which I learn that someone has a very strong dislike of something I personally quite enjoy. In fact, it’s starting to feel like I am immersed in a sea of people who really do not like the things I like, and that no place on the internet is safe from some jerk-wad popping their head up to tell me, “Hey, that thing you like, it fucking sucks and you are a nu-male soyboy beta cuck for liking it!”
It’s not fun. It’s not exciting. It’s actually really disappointing. This behavior makes it difficult to experience a game in a vacuum, because the negative takes immediately put me on the back foot, and instead of being able to view the thing I enjoy solely through the lens of my own personal enjoyment, I begin to think of ways to defend the thing against the nonsensical and usually totally baseless attacks against it.
In some cases, this feels impossible and puts a person into a position that feels strange. How am I supposed to defend a video game from someone who is upset that the female characters aren’t sexy enough? If I was telling someone about a video game I like, I would probably not even mention how attractive I find the characters, but now that there are people out there complaining about it, and I want to defend the game, so I feel like I have to speak up and go, Hey, actually, the characters in the game are pretty attractive! which then raises the question, “Why do you care if the characters are attractive, you 40-year-old creep?”
I don’t! I’m not some fucking loser who is obsessed with how attractive video game characters are!I swear!I wouldn’t even mention it if it wasn’t for thatfucking guy over there!
It’s ridiculous that the dialogue around video games has come to this, that the people who love and enjoy video games end up feeling like we have to defend games against outlandish accusations and conspiracy theories. We are put in a position where we feel the need to defend an RPG that has “pick your pronoun” options, a thing which should not require any defense at all, because no one in their right mind would be upset about it, as it is entirely inconsequential to anyone who does not feel any concern about their own pronouns.
You end up feeling like the only sane and logical course of action is to ignore these people, to let them enjoy their negative echo chamber, because fighting against them is too exhausting, too confusing, or too dangerous (depending on how outraged the mob becomes).
But if you are a person who cares, and you feel badly for video game developers who are getting laid off because these hate campaigns can be quite successful at poisoning the gaming community against an otherwise good game, you want to speak up and fight back. There’s also the aforementioned problem that, if you are a fan of games, you likely want to interact with other fans of games (because it is always more fun to enjoy a game as a group), but online spaces for gamers are being taken over by this kind of aggrieved antagonist and every conversation ends up being poisoned by all these sorts of tactics. You can’t escape it, there is no place on the internet dedicated solely to the enjoyment of a thing anymore; subreddits for specific games usually end up being a place where people complain about it more than they celebrate it.
So what can you do, really? If you fight back, you’re essentially just spinning your wheels. You’ll never get through to these gamers whose minds have been poisoned by negative content. You won’t convince a YouTuber whose livelihood depends on creating these hate-driven videos. And you’ll only be painting a target on your back for some internet loser looking to dox you. And if you do nothing, you risk sitting idly by while historic game studios are slowly dismantled by manufactured controversy.
It’s unfortunate, but the anti-woke, anti-liberal, anti-kindness contingent of the internet has amassed a large amount of power, thanks to social media algorithms that promote their rhetoric to those most susceptible to it, leaving people on the other side feeling pretty powerless to fight back against it.
For two solid decades, the internet was a safe haven for weirdos and outcasts to congregate and enjoy things together. Now, it’s an algorithm-driven hellhole—a bar full of angry, bitter people desperate to pick a fight. Worse yet, the bartender is paying them to do it because the fights keep people coming back.
About two years ago I released a screensaver for macOS called Ealain, and versioned it v0.1 because it was not quite living up to my original vision for the screensaver. And while it has grown in popularity regardless, I always knew it could be better.
Ealain is meant to be a macOS screensaver that is constantly creating new AI-generated images that grace only your screen. I wanted to power this functionality with the AI Horde, and have each screensaver generate its own batch of unique images.
But it was easier and faster to essentially fake that functionality by having one person (me) generate the images periodically and upload them to a CDN, for the screensavers to download from. This was less cool, as every screensaver would be displaying the same imagery, but much easier and faster to develop, and results in a nice immediate gratification when you start the screensaver and images show up right away.
However v0.1 had no local caching, so each time it displayed an image, it was downloading it from scratch from the internet. This made the screensaver something of a ticking time bomb for people on metered internet connections, and for the past two years it’s been bothering me that I put something so faulty out into the world, and I’ve been itching to fix my mistake.
Without further ado, I am delighted to present Ealain for macOS v1.0, a version of the screensaver that satisfies my original vision for it, as well as expands the concept just a tiny bit.
Here’s some samples of the kind of art you can expect to see in Ealain v1.0.
Ealain v1.0 now generates images directly from the AI Horde, using the AI Horde Style system. This new setup allows me to have the screensaver generate images for everyone, but use the kudos supply from my worker to pay for the generations. If I ever run out of kudos, it’ll continue to work, it simply start generating images more slowly.
You’ll be getting the same classic Ealain screensaver images (with a few changes to remove some generations I was never happy about) that you’ve been enjoying in v1.0, and now they will be unique for everybody. It’s essentially impossible that you will ever see an image that someone else has seen, which is pretty cool!
Portrait Display Support
Ealain v1.0 has another improvement, which is that it will generate unique art for monitors that are in landscape or portrait orientation. I have a computer setup with one landscape and one portrait display, and it’s always bothered me that the image displayed on the portrait display is just a ‘slice’ of the landscape image. Now you get full 9:16 aspect ratio images unique for that display, if you have one.
Customizable Style
Ealain v1.0 has gained one new feature, and that is the ability to override the screensaver style with one of your own choosing. This means that you can completely take over the screensaver and change the art style to something else. I’ll be thinking of and creating more styles that can be found in STYLES.md in the Ealain repo. Here’s one I created as an example, Cubism:
In my early teens and twenties, I was a consummate blogger. Well, really, I was more of a diarist, spewing thoughts about my life nearly continuously onto a blog of some form or another. In the late 2000’s, I decided to use my ability to spew text to promote music I liked, by converting my journaling domain staires.org into a music blog. The original conceit was that I would post a song every day, for at least a year, complete with a personal anecdote about my personal connection to the song, or at the very least a couple paragraphs of my thoughts and opinions on it.
I believe I made it up to around day 230 before I decided I could not keep up the daily pace and started posting less frequently. But that was a lot of time to do the daily posting consistently, and it got me some early attention. Eventually I got picked up by Hype Machine, which helped promote the blog further. They still have an archived list of 208 staires! songs that they syndicated, which is pretty cool to see. Over time, I built up a small following and made some lifelong music-loving friends along the way.
But life, or mental illness, or monetary troubles got in the way and I eventually stopped updating it. I gave up. I guess I lost the love of the game? I forgot what the point was? I was going through a lot of stuff in the early 2010’s, so who knows what my exact reasoning was. In a bit of a snafu, when I cancelled my hosting for the website, the host ended up turning off auto-renew for the domain. When it came up for renew, they registered it for themselves and wanted to charge me hundreds of dollars to get it back, which I did not have. And that’s why the staires.org domain was advertising car parts and other junk for a long time, probably over a decade.
A couple days ago, I randomly typed the domain into Squarespace, and it said it was available. I was shocked, and I bought it immediately, without thinking much about it, just glad to have it back with me where it belongs. But then I realized today, I’ve never stopped writing about music I like, recommending it to others, I’ve just been doing it privately, directly to friends or small community chatrooms. And in a lot of cases, when I do it that way, I’m just shouting into a void, and most people aren’t even paying attention. What’s the point of doing it that way?
At least if I write a post on a website, it’s something random people can run into. People who enjoy the songs I post can add me to their feed reader, or subscribe via email these days, and I can go back to promoting the music I love to a possibly wider audience.
So, without further ado, you can find me blogging about music again over at https://staires.org. Enjoy!
I noticed a lot of people ask in the AI Horde Discord how to run a worker. I thought it would be useful if the community had a blog post to point people to, and maybe that can be this post. Let’s go!
How to get an AI Horde API key
Be sure to get an AI Horde API key if you don’t have one. You can register here: https://aihorde.net/register. Be sure to protect this API key, put it in your password manager or somewhere else for safe keeping. This API key will be your ticket to all the kudos you can earn.
How to Run a Text Worker (“Scribe”) on Windows
If you’re using Windows, you’re in luck, because running a Horde worker is easier than ever thanks to Koboldcpp, which compiles all the bits and bobs into one executable file for you.
Step 1: Download Koboldcpp
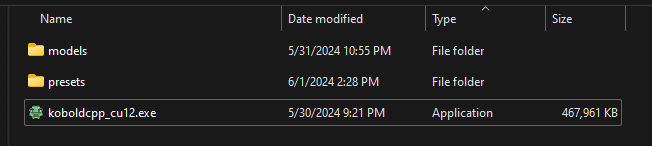
Go to the Koboldcpp Releases page, and grab the executable most relevant to you. This is probably koboldcpp.exe. If you have a newer Nvidia GPU, grab koboldcpp_cu12.exe. Stick this file in a folder somewhere, like D:\koboldcpp\koboldcpp.exe
I like to make a presets and models folder in here, so your folder might end up looking something like this depending on which version of koboldcpp you downloaded.
Step 2: Download a Model
Koboldcpp can run models quantized in the GGUF format. What does that mean in the most basic sense? Koboldcpp can run models that are compressed in a way that allows them to run on lower-end hardware, with some trade-offs (like decreased quality of generations). For example, CohereForAI/c4ai-command-r-v01 requires ~70gb of VRAM in its original form, but a 4-bit quantization (available here) of it only requires ~23gb of VRAM.
We’re going to focus on a model that everyone should be able to run locally, Sao10K/Fimbulvetr-11B-v2, which is a smaller model that really excels at roleplay chat, and there is plenty of demand for it on the horde. It’s a personal favorite of mine as well.
Step 2.a: Find a GGUF version of the model
Google (or use your search engine of choice) “<model name> gguf”, in this case we’ll look for “fimbulvetr-11b-v2 gguf“. Usually the first result going to huggingface.com is what you want. In this case, we’re going to end up on the second result, at mradermacher/Fimbulvetr-11B-v2-GGUF, because it gives us more options in regard to quantization sizes.
Step 2.b: Download a GGUF version of the model
You can see on the model page for that GGUF version, that there is a chart that tells you how “good” the various quants are, but here are some general tips:
Models hosted on the horde should be Q4 or greater, to ensure best generation quality.
You should pick the largest quant that looks like it can fit in your GPU’s VRAM.
If you have a 8gb GPU, get a model under 8gb, etc.
If you aren’t sure what to try, try Q4_K_S first. You can always download a bigger quant and try it later.
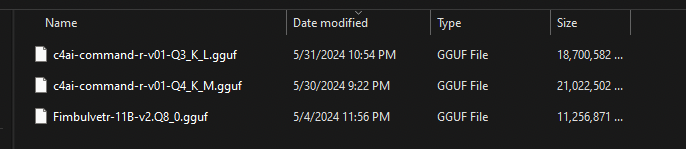
Download the .gguf file into your koboldcpp/models folder. My models folder looks like this:
Step 3: Configure Koboldcpp
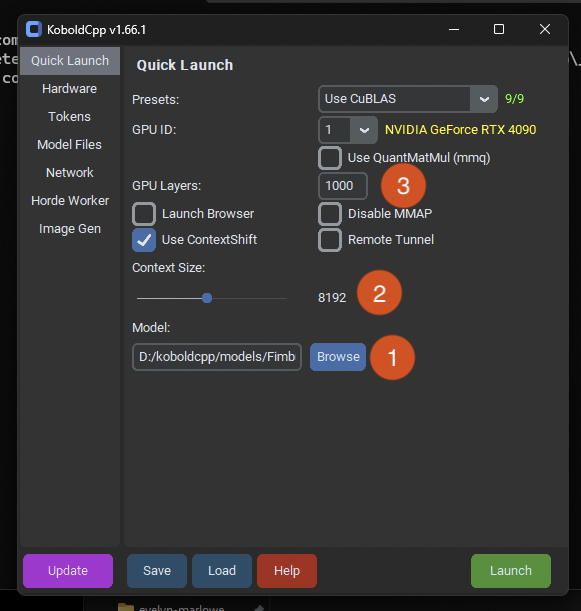
Now we’re ready to launch Koboldcpp and start configuring it. The initial Quick Launch screen has all the main information we need to worry about.
Hit browse and pick the .gguf file you downloaded into your models folder.
Set the context size you want. I like to have plenty of room for context, so I pick 8192 by default, but if you have less system power you should try 4096 to speed up generation times.
If you’re certain the model will fit entirely into your VRAM (because you downloaded a model smaller than your available VRAM), set a large number here. If you don’t know if the model will fit into your VRAM, there will be a section below about figuring out layer quantity.
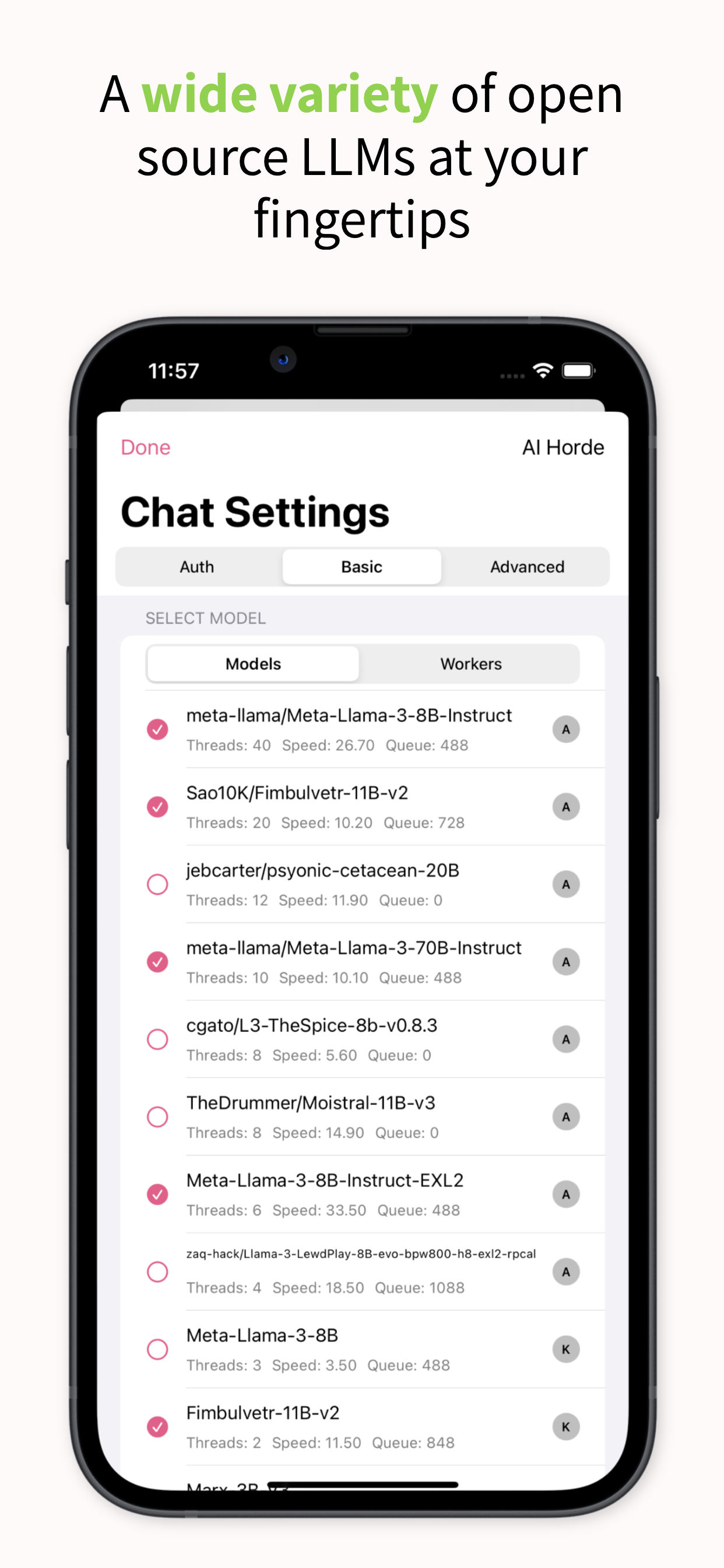
The model name is very important to get right, as it determines how much kudos you will get for your submitted generations. If you put an incorrect name here, you will get very few kudos. To makes sure you put the right name, check the model whitelist for the name of your model, without any quantization naming attached. In this case, we see that the base model of Sao10K/Fimbulvetr-11B-v2 is in the list. But that isn’t the name we want to put into the “Horde Model Name” slot, we want to identify that the model is being run with koboldcpp, so we put in the model name as “koboldcpp/Fimbulvetr-11B-v2”. Nothing else matters, you do not need to include the quantization level in the name.
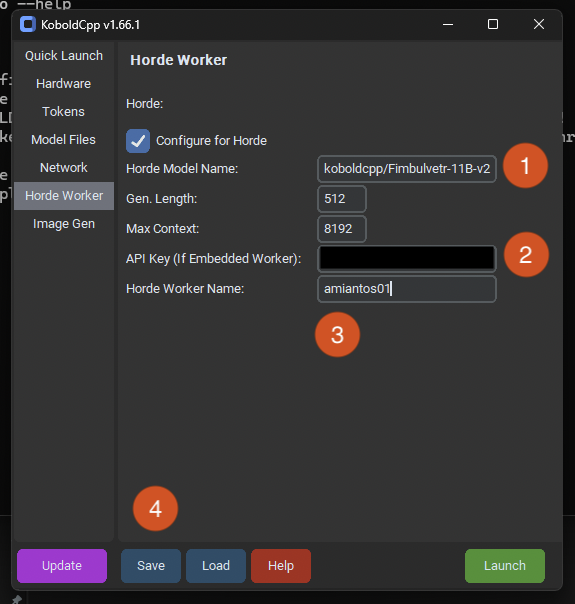
This is where you put your API key so you can receive kudos properly!
Your worker name should be the same every time you run your worker, regardless of the model being used.
Save your configuration to a .kcpps file so it is easy to reload it later. This is what the presets folder is for, save your configurations in there so you can easily use them later on. ⚠️ Koboldcpp doesn’t save your settings automatically!
Once your configuration is saved, hit Launch!
Step 4: Is it Working?
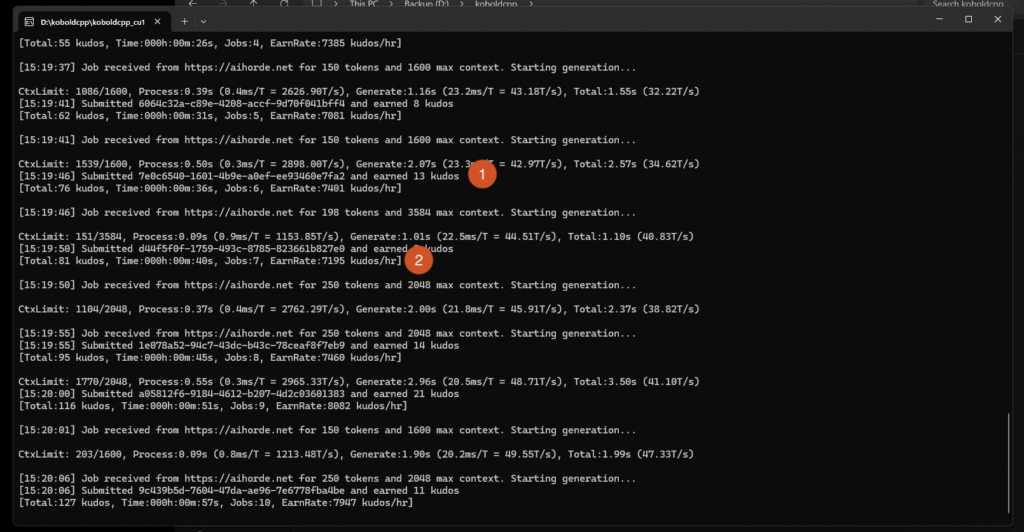
Once your worker is running, you should end up with a terminal display that shows you what your worker is up to. It looks like this.
This is how many kudos you are earning for this specific job. If this number is very low, like 1 or 2 kudos, you likely have your model name configured incorrectly or the model is not whitelisted for the horde. Double check that your model name is correctly entered and that the model is whitelisted.
This read out shows how many jobs your worker has completed and how many kudos per hour you are making. If you’re not earning several thousand kudos per hour, your worker is likely configured incorrectly or you’ve picked a model you are not able to run at a decent speed.
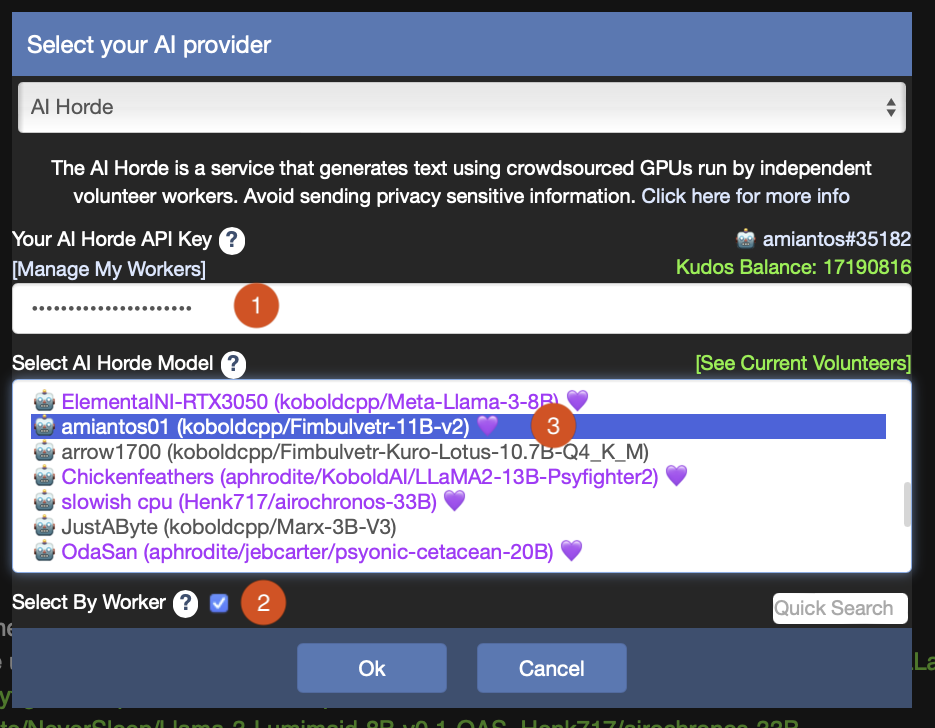
You can test your worker through the horde by using Kobold Lite. Load up the website and then click on the “AI” button in the top left corner.
Put in your AI Horde API key if you haven’t before.
Check the box “Select By Worker”
Look for your worker in the model list. If you don’t have a Purple Heart here, it’s just because your worker is not yet “trusted”. More on that later.
Click OK, then pick a desired scenario (KoboldGPT is the easiest for testing, I think) and submit a chat request. You know your worker is running when you get a message back and it shows your worker name and model name in the bottom of the client, like this:
If you ended up here and all looks well, congratulations, your worker is running and racking in the kudos.
Troubleshooting
“Where are my kudos? I’m not getting the right amount of kudos.”
To prevent abuse of the horde by bad actors, when you first start running a worker, half of your earned kudos are held in escrow. After a week or two of running a worker without issue, you’ll become “trusted” and receive all kudos owed to you (the kudos held in escrow plus all future earnings). (By “without issue”, I just mean that your worker is returning proper generations and there is no monkey business happening.)
“What was all that about layers and how can I run models larger than how much VRAM my GPU has?”
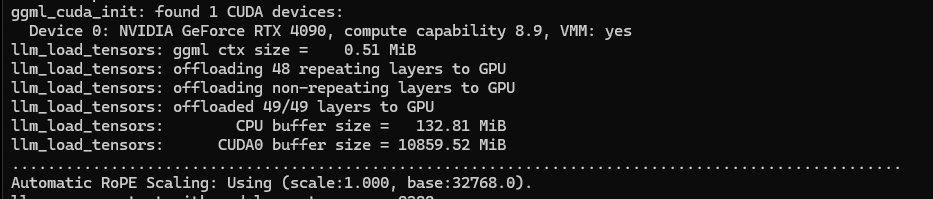
When you are configuring Koboldcpp, it asks you how many GPU Layers to use. This can be useful if you want to run a model that is just slightly too big for how much VRAM your card has. But how many layers does each model take up? There is a way to guess this yourself, but I like to just try to load the model in Koboldcpp and see what it says. For example, the 8bit quantization of Fimbulvetr I’m using displays this in the console when loading.
You’ll see it says that this model had 49 layers that it is loading in the GPU memory. If we didn’t have enough memory to store the full model, we could configure Koboldcpp with GPU Layers set to 40, and then it’ll load most of the model to the GPU, and the rest to system memory for the CPU to use. This can be very slow, so it’s recommended to only offload as many layers as needed to run the model at all. The more layers on the GPU, the better!
“I need more help!”
Not a problem at all, there are a lot of people who are willing to help you over on the KoboldAI Discord. There are lots of people far more knowledgable than I am, and if you decide you like running a worker a lot, they can help you level up your hosting game. Remember, this is just the most basic guide, there are more robust methods (like aphrodite) that allow you to run several models at once if you have the hardware capable of doing it. Feel free to ask about that in the Discord.
While most of my AI related app releases have been dedicated to image generation, (counting two Ealain releases and then Aislingeach), my gateway into generative AI was chatbots. If you look at the chronology of this blog, that’s pretty obvious, since it all began with my post about “uncensored” chatbots, which I’ve recently updated to note this very app I’m talking about now.
So, yeah, it’s weird that it took me nearly a year to finally make my own chatbot app. The reason for this is largely just that open source LLMs took a little time to cook before getting better. They’re still not perfect, or anything, but they’re a lot more fun to play around with and you can essentially get a good experience “out of the box” with any of them. It felt like the time was right to try to make a straight-forward app for character-based role-play chat.
If you don’t care to read the rest, well, here’s some links for you.
It feels moderately awkward to explain this app to people, because the main way LLMs are in the news and overall public consciousness is that they’re writing assistants, or coding assistants, or maybe they’re going to steal customer service jobs. But this app is not that, it’s not meant to be an assistant. It’s meant to allow you to chat to fictional characters, which at face value sounds… immature? Or stupid? I don’t know, but it definitely makes me cringe a little bit.
Additionally, as my original blog post makes clear, depending on the audience, there’s a bit of ick around the entire subject matter because a lot of the reason these open source LLMs exist and are good for this purpose is because people wanted to have sex with chatbots. That’s just how it is. There’s a lot of lonely (or just horny) people out there, across the whole spectrum of genders and sexualities, and a vast pornography industry in existence that proves it. So, of course people want to use this new technology in that way.
So is that an explicit endorsement, that my app is for people to use to have sex with chatbots? Well, that’s the pickle I’m in with the app, when I’m explaining it to people, because it’s hard to convince someone that a grown adult might just enjoy talking to random fictional characters. And that’s mostly how I dogfood the app, just shooting the shit with random character cards, and seeing what funny (or stupid) stuff comes out. This technology can be really entertaining, especially when it pulls a stroke of genius out of its back pocket and surprises you.
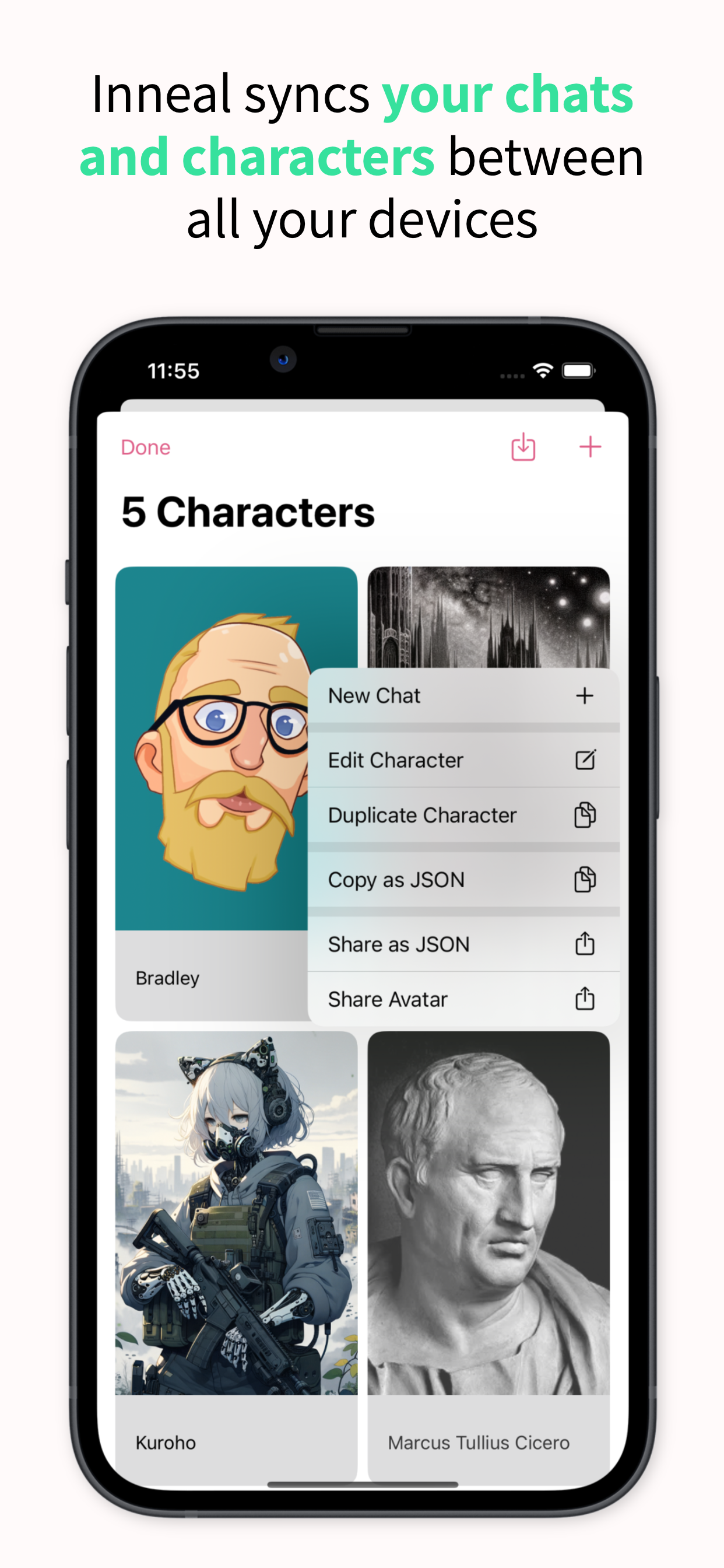
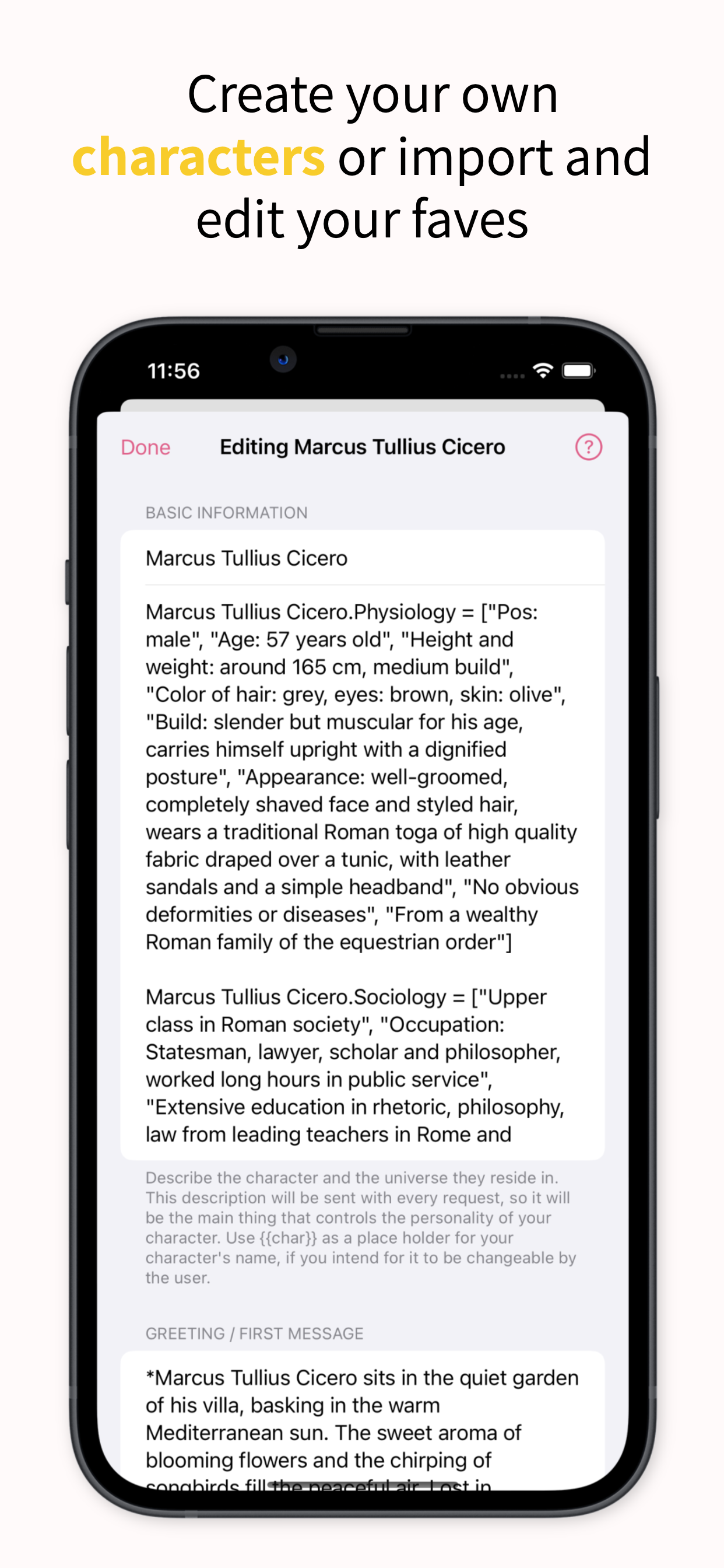
So, Inneal is for writing characters and chatting with them, and maybe that is just for fun, like a choose your own adventure story you are actively writing while participating in it; or maybe you do it to stimulate your creative instinct and try to flesh out characters in your own fictional stories; or maybe it’s because you’re lonely and you want to talk to a familiar face, even if they don’t really exist. I’m not going to judge. I’m not the judging kind of person. Even if you want to have sex with them.
This is my second app built entirely with SwiftUI, and my first app using SwiftData for the persistence layer. Ealain, my first SwiftUI app, was pretty simple and didn’t really force me to learn how SwiftUI works properly. Inneal, on the other hand, really forced me to learn quite a bit about SwiftUI and especially how it interacts with SwiftData.
When I’ve used CoreData in the past, I’ve followed advice to abstract it away as best I can and I usually keep all the CoreData related logic compiled together in one class, to try to avoid issues with threading. This results in crashes in Aislingeach to this day with NSFetchedResultsController, but, whatever, they’re pretty rare.
SwiftData doesn’t want you to do this, or at least, if you do, you lose out on a lot of cool stuff. It also doesn’t want you to update or create model objects essentially anywhere but directly in the View code. This feels weird, coming from a background where you feel inclined to try to hide the model away from the views as much as you can. Instead I end up in a situation where the ViewModel is passing data back to the View so that the View can create or update the Model within itself.
I don’t think I am doing this wrong, because it works quite well, and still keeps almost all the backend logic tucked away in the ViewModel, and the View has this strangle-hold on the Model, which sort of makes sense because that is where the model is used and updated anyway.
SwiftUI is a little glitchy, but it’s understandable because I don’t envy any of the behind the scenes work that goes into it. The two notable issues I ran into are: 1) if you setup SwiftData the way Apple intends and then setup CloudKit syncing, your app will crash every time it’s backgrounded. 2) When you use LazyVStack with defaultScrollAnchor, sometimes your internal views just kind of disappear, which is a continued issue I can’t manage to solve 100%. I might end up using one of my free developer technical support tickets to ask about this issue.
The other issue I’m sure is perennial, which is that you will reach a point where the compiler simply dies instead of making any attempt at telling you where the bug in your code is. This means you must be very careful about how many code changes you make before doing a build & run, because otherwise you’ll end up pretty stuck not having any idea what you broke.
All that said, I really enjoyed building this app with SwiftUI and don’t think I will go back to using UIKit unless I really have to for some reason. It really sped up the development process and cut down on a lot of unnecessary boilerplate style code created by strict adherence to the delegate method.
I guess that’s it. Go download the app and chat with some bots!
I think that post is still worth reading, because it explains more in depth what we’re talking about exactly, and why, and I am going to take a stab at cutting to the chase and just updating a couple specific points from that post.
Previously, I said that you could get a pretty good chatbot experience out of OpenAI’s APIs, and you should try that first. That is no longer the case. Big corporate LLMs have implemented aggressive content filtering that really restrict your chatbots in ways that they weren’t 11 months ago. That isn’t to say corporate LLMs don’t have their uses, but if you’re looking for “uncensored” LLMs, which is the point of this post, I can no longer recommend OpenAI, Google, Anthropic, etc.
Previously, I said that currently available open source LLMs like Pygmalion 6B “weren’t very good”. That is, thankfully, no longer the case. Specifically, I think a model named Fimbulvetr is very good and you can likely run it at home very easily, or find it hosted on the AI Horde usually. I think this takes a lot of the sting out of commercial LLMs becoming very sanitized and being turned into the equivalent of hammers and wrenches.
Some things have also changed with the software that you can use to run models. There’s a lot of it. I am going to reference the things I have used specifically and can recommend depending on your circumstances. Without further ado, here we go…
We’re going to start at the lowest level of effort and work our way up as we progress into the hobby. Sounds fun, right?
An Easy and Free iPhone / iPad Client
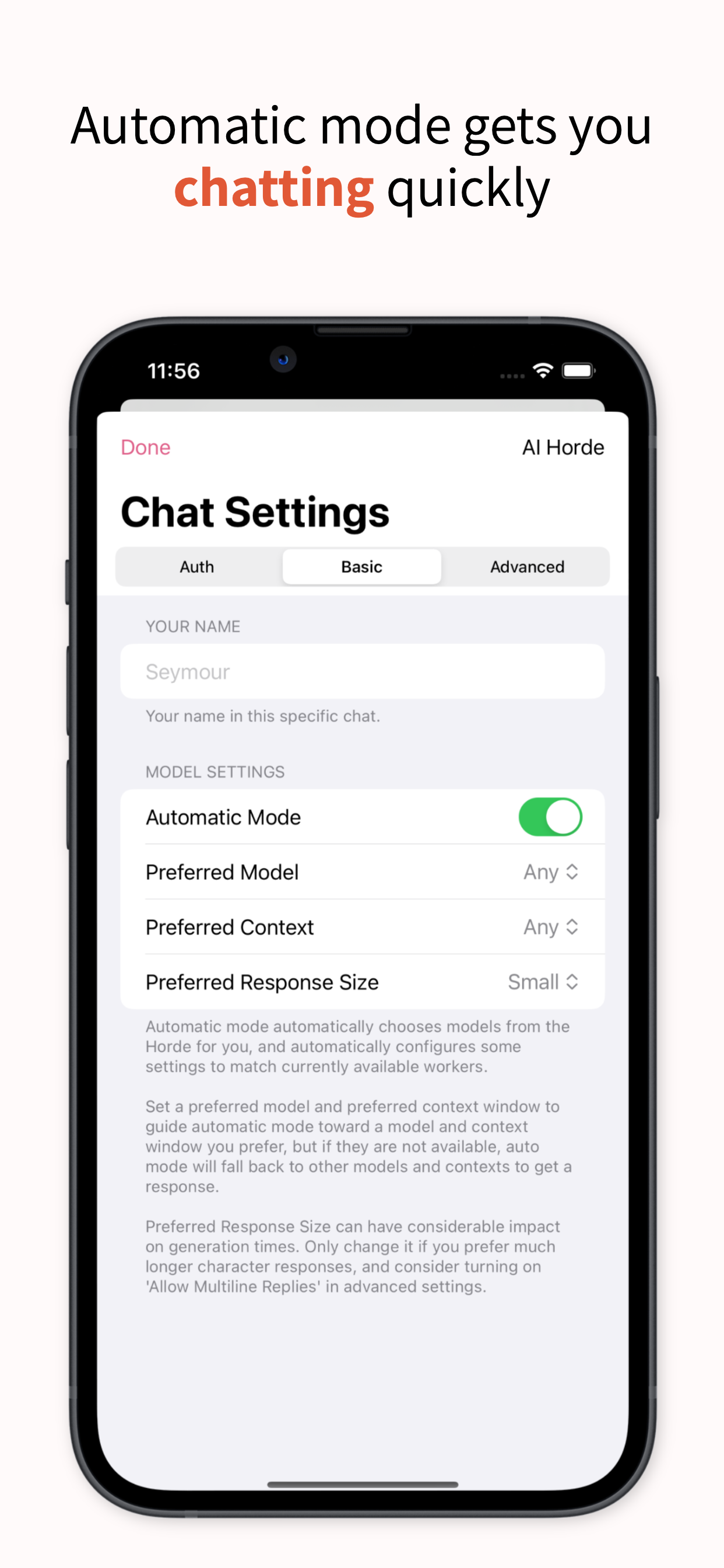
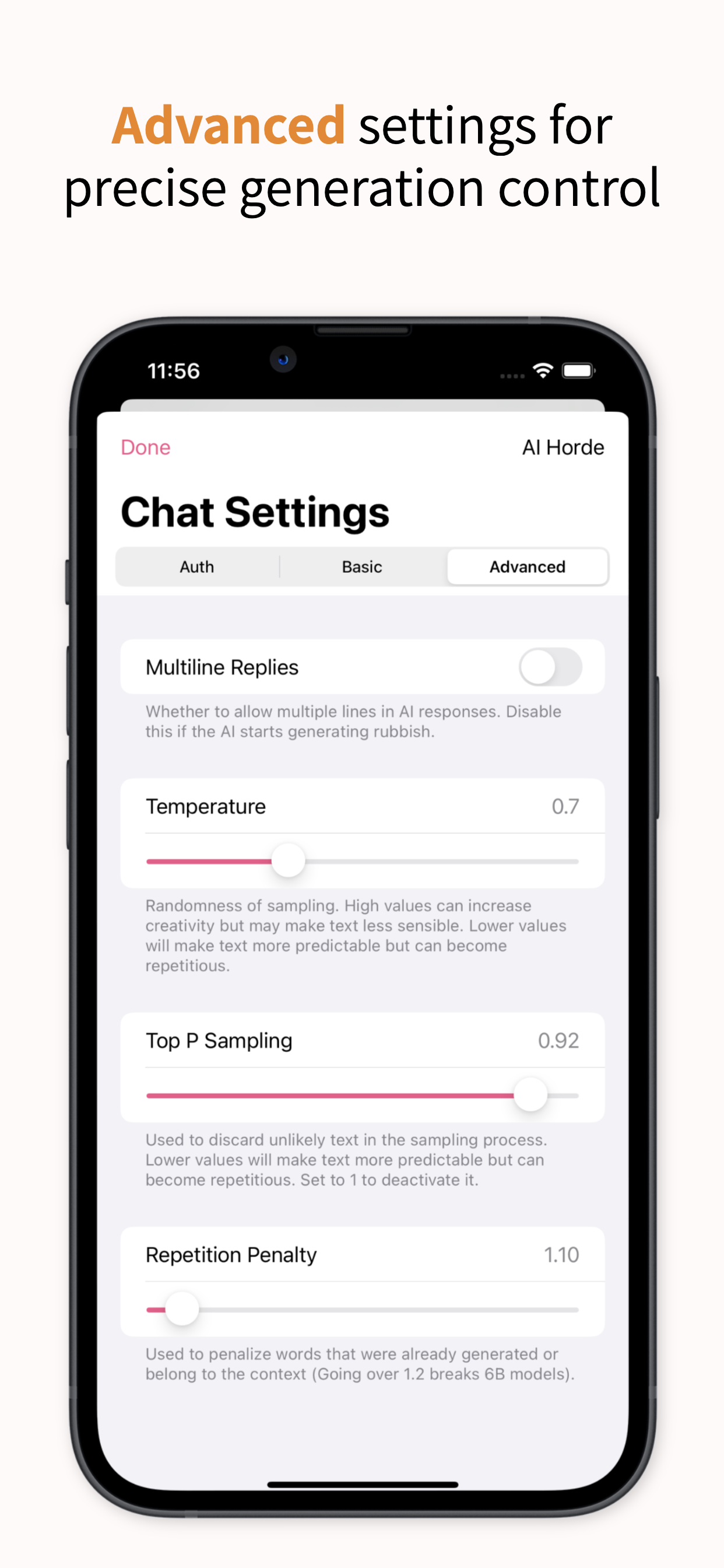
Do you just want to chat with some bots to see what it is like, and not spend any money or time on it? I just released an iPhone / iPad chat client for the AI Horde, called Inneal. It’s free, and use of the AI Horde is free. It also hides away some of the fiddly bits that can be confusing in other clients, so you can start importing character cards and chatting with them right away. Yes, this is self-promotion, but I made this app specifically to make it dead simple to start chatting right away.
Once you’ve become a bit bored with what you can do in Inneal, you can branch out into another free client for the Horde that does some other things, called Kobold Lite. The interface for this app is a bit confusing but you can also import character cards from CHUB, and do some other stuff in this client, like use straight text completion, or Adventure Mode which tries to do kind of a Zork type thing. It’s pretty neat.
If you want to get really deep into using third party web clients, and I don’t honestly recommend it, because why would you want all your chats stored on some random server somewhere, there’s a very nice website called Agnai that supports a lot of chat features that are becoming a standard, like lore books. This client supports lots of LLM APIs as well as the AI Horde.
If you’re computer illiterate and you have money, there are plenty of paid sites where you can chat with bots for money. Some of them have some very large models you can use, which should, in theory, be better at chat than smaller models. I can’t say whether any of these sites are good or not, and I wouldn’t personally use them myself. I felt it would be unfair not to mention them, however.
If you’re computer literate, and you want to keep your chats on your computer where they are safe, you should consider installing SillyTavern. In addition to being fully under your control, it seems to be the gold standard client at the moment for chatting and is jam-packed with features. I just wish they’d change the name.
SillyTavern can connect to the horde, of course, so you can use this freely still, but really, you should start running your own models locally if you can, which we talk about next.
Running models at home is easier than ever before, with some caveats, namely that you’re running quantized models, which means they may not be quite as good as the full-sized models running on server farms with tons of VRAM available. But they still do the job better than anything else that has ever existed, so, nothing to complain about, really.
If you’re running Windows
If you’ve installed SillyTavern and you’re using it, then you’re definitely serious enough to run your own LLMs locally, and if you have a gaming graphics card made in the last couple years, you probably can easily run Fimbulvetr locally. I’ve used Koboldcpp to do this on my PC lately.
You’ll want the Fimbulvetr-11B-v2.q4_K_S.gguf file from the link below. This is a quantized version of the model that will run on smaller GPU graphics cards, like 8 GB of VRAM. But it also runs well and works just fine on bigger graphics cards.
If you have an M-series Mac, you can use Ollama to run models locally, and the version of Fimbulvetr available under Ollama runs really well on my M2 Pro mac Mini, and SillyTavern has an Ollama specific connection in it already.
If you had fun getting Fimbulvetr working, congratulations to you, you’re just getting started. There are a lot of cool models out there, and a lot of stuff to learn about (like Instruct Mode). I recommend checking out this page that reviews LLMs based on how good they are for chatbot roleplay. It’s updated quite often. Chronoboros, Psyfighter2, Noromaid Mixtral, … there are a lot of fun models to try out to see what works best for what you like.
Also, go back and read my original post, if you didn’t, there’s some other stuff in there and if you’re all the way down here, you must love reading, so do it some more?
That’s it for now! I’m sure there will be another update, perhaps this year or next year. Just in the past month, we’ve seen the release of Command-R and Llama 3, two very large open source models that are sure to help push forward progress on these fronts. We’ve also seen corporate AI get more and more restrictive about how it can be used, as world governments begin to make moves that could enable regulatory capture, making it more important than ever before that these fields move quickly. Kudos to the torch-bearers.
I’ve built a few apps now, apps that people actually pay money for–not a lot of money; a very, very small amount of money, but enough that my Apple Developer fee has been paid for until I die, at the very least. I don’t say this to brag, but to establish that I’ve done this a few times now, entirely by myself, so I can speak somewhat authoritatively about it. Why is that important? Because I want you to achieve your goals, and if your goals are similar to what I have achieved, then maybe this guide will help you reach them. So, this is how (and why) I build apps, so you can too.
Why I Build for Apple Platforms
The iOS ecosystem, starting with UIKit and now with SwiftUI, allows you to quickly build beautiful apps that feel great to hold in your hand and interact with. If you already enjoy using Apple platforms, especially for desktop computing, it’s a no brainer, as you have all the tools you need for development already.
In conversations with people getting into development, they seem almost mindlessly compelled to pursue JavaScript based front-end web development. I find that realm of development to be very complex, especially for a beginner, and that the end result (a web app) does not feel as nice as a native app. Sure, you can use your app on any device with a web browser, but, who cares, it still feels like a website, yuck.
That said, my development process has nothing particularly to do with the platform I build for. But I do recommend choosing one platform and dedicating yourself to it completely, at least at first.
Why I Build Anything At All
I build the apps I do because I want them, for myself. I highly recommend that you build software you want. If you are chasing fame or profit, it pays to be a curious person, because you will stumble into new interests and hobbies, which exposes you to new people and new experiences, and may create new wants in you, which lead to new app ideas. This is almost the entirety of how I get any ideas at all.
Incremental Dogfooding
Dogfooding, short for “eating your own dog food”, simply means using your own product. Because I am building apps I want, to fulfill some workflow I’ve envisioned in my head, dogfooding is an inherent part of the process. This leads to a very incremental development process that forces me to logically break down the workflow into a series of steps that allow the app to naturally grow over time.
For example, I have been working on a chatbot client. It was immediately obvious what the first goal would be: I want to be able to type a message into a box, send it, and get a message back. It doesn’t matter at this point whether or not the chat is saved or even what service the chatbot is using, I just need to get the most basic component of this project working.
In the case of Aislingeach, the most basic component of the project was to type in a prompt, and get a single image back from the horde. In the case of Ealain for Vision Pro, it was simply to get images to download and appear on screen.
For none of these apps did I really concern myself with the visual design of the app at first, which is easy on Apple platforms, because Apple has very strong platform conventions that I appreciate and if you use UIKit or SwiftUI properly, your app will end up looking nice. It may be tempting to nail the visuals of your app upfront, but it doesn’t make sense to spend a lot of time designing something you might not be able to build, or might not even like when you do build it. Design and polish later, when everything is working. Remember, “design is how it works, not how it looks,” at least at first.
Annoyance Accrual
Once I get the most basic workflow working for each idea and see how it feels, this often motivates me to continue the process quite naturally, because I will usually feel some sort of annoyance with what I have built so far. This the same sort of feeling that I get when I’m using other software and it doesn’t work quite right, or look very good, but in this case, I can do something about it, because I’m the code jockey building the thing.
What’s nice about this process is that it simulates the ebb and flow that is essential to any interesting and exciting activity. Movies, music, literature–these are things that take you on an emotional journey of ups and downs, ideally. This development process is the same: You are scared at the start (what if I am too dumb to do this?), but you get a piece of the app working, so then you are happy. You turn happily to use your app, and find something annoying about it, so now you’re mad and maybe a little scared still (what if I can’t fix this?), but then you fix it, and now you’re happy again. Rinse and repeat.
In the case of my chatbot app, once I got basic chat working, the next big annoyance was persistence: I want these chats to stick around, it was lame they disappeared when the app restarted. So this forced me to start thinking about the data model for the app and make a decision around that issue. Once chats were stored in some sort of database, it was annoying that the chatbot had no personality, so I had to implement importing characters and using them in the chat prompts.
Once I could talk to a character, the next annoyance was that the LLM sometimes generates something lame, and you want to tell the LLM to “retry”, basically a message delete and regenerate. After that was implemented, it was annoying that I couldn’t just edit or delete messages, so that was next to get built. After this point, the most basic workflow is almost entirely in place, which means future annoyances will mainly be around refining and improving that core workflow, by adding additional screens for configuration options and supporting content like that. (Eventually the “retry” option became an annoyance, and I replaced it with SillyTavern style swiping, a much better feature.)
All throughout this process, I’m actively dogfooding the app, which acts as a built-in quality assurance (QA) process. It also forces me to think about the user experience (UX) of the app, because I am actively using it and accruing minor annoyances with how it looks and functions along the way. For the chatbot app, I wanted to make sure the experience of using the chat interface felt very native, like iMessage, which necessitate a lot of research and iteration. I try to tackle these UX annoyances as they pop up, usually between resolving the core annoyances. Shifting between building core features and refining the user experience helps keep the development process fun and dynamic for me.
Release As Soon As Possible
Perfect is the enemy of good. This is a fact that cannot be argued with. If you try to achieve perfection, to truly whittle down your list of annoyances to absolutely nothing, you will never get there. This is the plight of a human being; If we were capable of ever truly being satisfied, we would stagnate and die as a species. I don’t mean to get too philosophical, but it’s important for your own sake to internalize this idea, so that you release your projects and let people use them, instead of just fiddling with them until you lose interest and forget about them.
Because I’m building apps that I want, for myself, and I pretend that I don’t really care that much about what other people think because I assume that “if I like it, it must be good”, it feels relatively easy for me to reach a point where my list of annoyances naturally turns into a list of trivialities and bigger wants. At this point I know the app is ready for a 1.0 release.
The trivialities can be wide ranging, from not being happy with the way code is structure in the project, to the design of minor interface elements. The bigger wants are things that feel like they should be in a 1.1 or later release, like adding additional features that refine or expand the app, or completely redesigning entire parts of the app that grew a little stale on the road to 1.0. The important thing is that none of these things truly hurt the core workflow the app is meant to support.
What is great about releasing your app as quickly as possible is that you get to collaborate with other motivated, passionate people on expanding your lists of annoyances, trivialities, and bigger wants. In my case especially, because I am building out my workflow for a process, after the app is released, I end up discovering glaring blindspots in my knowledge of that process that are only revealed when other people explain their workflow to me. And because there is now a real person asking for my help in achieving this with my app, it really motivates me to figure out how to accommodate their need, while still adhering to whatever my vision of the app may be.
After that happens to you, congratulations, you are officially an app developer. You built an app, you got other people to use it, and you listened to their complaints and incorporated their feedback. This is the entire process of being a software engineer, from top to bottom. Everything else that happens in the professional world around software engineering are just additional layers of refinement built on top of this sort of process, to scale up to supporting multiple engineers working on a single project.
Just 11 days ago, I released Ealain for Vision Pro and now I’m very happy to introduce Ealain for Apple TV, which is the same app, it’s just for Apple TV now.
You can find it at the same App Store page for Ealain for Vision Pro, because it’s a universal app (or whatever they are called), one purchase gets you both version.
I was able to reuse a lot of code from the Vision Pro version, which was useful, but also had to rethink the UI of the configuration screens so it made more sense on a TV. In some ways, I prefer the artist picker in this version and may find some way to bring it to the Vision Pro.
I don’t have a lot to say about it, but it’s neat and a nice addition to any Apple TV 😉
I wrote several within the first week I got the headset but none of them seemed to be saying anything that wasn’t already being said. Now that the honeymoon period is likely over for most people, and the AVP Discord is getting much quieter, maybe it’s my time to share.
The Apple Vision Pro is a fantastic prototype of what the future may look like. But it’s just a prototype, deep down, with a lot of shortcomings that turn the AVP into a fancy paperweight on my desk. It sounds harsh, but it’s true. This is not a real product for normal people to use. It’s not even a real product for a tech enthusiast to use.
The first thing anyone is going to think or say when they put an AVP on their head is: “Good lord, this thing is heavy.” It is very heavy. The straps included in the box do absolutely nothing to reduce the amount of weight or pressure you feel on your face or head. Even with a third party top strap, the comfort is terrible. I am a dedicated enthusiast and I still have not managed to wear my AVP for longer than 30 minutes at a time because it is very uncomfortable and hot to wear. My Quest 3 + Elite Strap with Battery I’ve worn for 4 hours straight, if not longer, but that’s not a fair comparison, because the Quest 3 actually had some experiences worth diving into for hours at a time. The AVP does not.
This means that the second thing anyone is going to think after using the headset is, “That’s it? What am I supposed to do with it now?” After the dinosaur app, and seeing a Disney+ movie in 3D HDR, there’s just no real use case for the headset. At first, the defense for this take was that the AVP is a productivity device more than it is a gaming device like the Quest 3, because it clearly wasn’t built with gaming in mind. But the deeper truth is that the AVP is not a good productivity device either.
There are no benefits to using the AVP over just using your monitor at your desk. “But, you can have infinite displays!” No, you can’t. You get one Virtual Display and then you can put apps all around you, sure, but what good is that? I don’t want to be constantly turning my head and body around to look at apps. I want to “three-finger swipe up” to see all my windows in Expose, then pick one to focus on where I am already looking. Very occasionally I will side by side two apps on my display. But, I don’t want to keep turning my head all day long, which is why I use a single ultra wide display and no secondary monitors.
There is absolutely no window management in visionOS, no Expose, which quickly makes any productivity oriented task frustrating and cumbersome. Apps become obscured by other apps, completely vanishing from view, leaving you to sit there pinching and dragging windows all over the place til you find the one you really wanted.
As an example of how half-baked window management is in visionOS, if you are using Virtual Display to control your Mac while you are using Xcode to build an AVP app, every time you build and run your app, it will pop up directly where you are looking when it launches, which is usually right over your virtual display. So every single time you build and launch your app, you have to pinch it and move it away from the virtual display so you can see both at the same time. You quickly learn that you should hit build & run and then quickly look off to the side so the app launches somewhere else, but this is completely insane. Why can’t visionOS remember where the window was seconds ago and put it back in place? Did anyone working at Apple ever use the AVP for development? I really don’t think so.
The deeper issue here is that visionOS is based on iOS, and it has all of the issues that iPads and iPhones have when it comes to productivity. The apps are all Playskool versions of the real apps, even in comparison to their iOS counterparts. There’s no terminal, no real file system, no “real apps” for the platform (depending on your use case, and depending on if you count iPad apps).
If you want to do software engineering, you’re stuck using Virtual Display, or else you’re such an enthusiast that you’re willing to try to use VS Code tunnels to use VS Code through a web browser, which introduces input lag that feels awful to me. What are the chances we’re ever able to do software development fully natively on the Apple Vision Pro? Probably 0%. How long has the iPad been out? 13 years now, right? And can you develop on it? Nope. (Not unless you’re willing to deal with a lot of headaches, I assume, similar to how I see people using the AVP for engineering.)
Past that, all my complaints are possibly pretty niche. You can’t play two videos with audio on at the same time, which may be a niche use case, but it’s still a pretty strange shortcoming considering macOS can play any number of videos with audio all at the same time without issue. AVP doesn’t come out of the box with enabled support for WebXR, so 3D YouTube videos and other content doesn’t work. If you go and turn on a bunch of extra options, you can start watching 3D video on the web, but because there are no controllers with the AVP, none of the open web has been built to deal with it so you can’t really control anything. The Photos.app doesn’t allow you to create albums and you cannot put photos into albums, it’s just a dumb photo viewer for the most part.
There are a lot of people still in the honeymoon period, people who are very committed to the idea and it allows them to overlook all the shortcomings and issues. Kudos to those people, I wish I could be one of them. But I can’t. The truth is that I have no need for the one thing the AVP does well, which is movie watching. It’s a beautiful way to watch movies if you don’t have a similarly expensive home theater setup at home (and you don’t mind all the glare in the lenses, which ruins the experience unless you watch movies on the moon which balances out the glare).
In that context, the AVP is a pretty okay portable one-person home theater setup. But everything else it’s supposed to do? It doesn’t do any of them at a level I would consider acceptable. Maybe if the AVP was half the weight and it was more comfortable to wear, it would be easier to overlook these shortcomings and enjoy the glimpse of the future it provides. But at the moment, the future seems a little hamstrung by the constraints of iOS and the unnecessary weight of the device.
Unfortunately, the Apple Vision Pro is not really “a computer you strap to your face”. Deep down, it’s “an iPad you strap to your face”, and that’s probably the cruelest thing I can say about the device.
If you’re curious about the promise of head mounted displays, I’d highly recommend a Quest 3 over the Apple Vision Pro. It’s worse than the AVP for productivity use (because the screens are too low resolution in my opinion), but you’re getting a much more fully featured headset for a significantly lower price and you can do a lot more with it out of the box. Neither product is perfect, but the AVP is clearly a prototype geared toward enthusiasts, while the Quest 3 is widely used (and beloved!) by every day normal people all over the country. Full disclosure, I hardly use my Quest 3 these days, but I still think it is a much better way to dip your toes into standalone VR than the AVP.